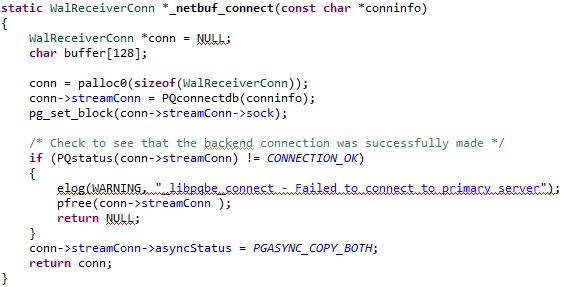
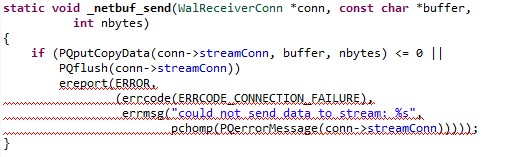
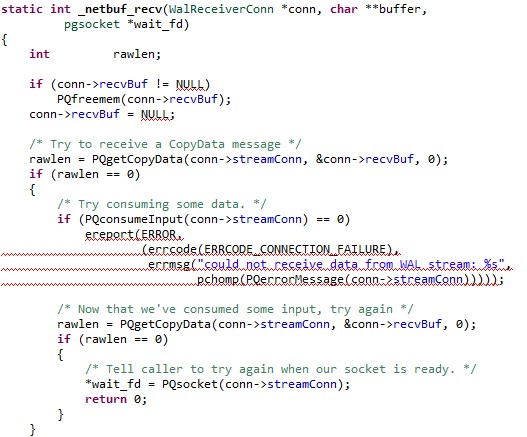
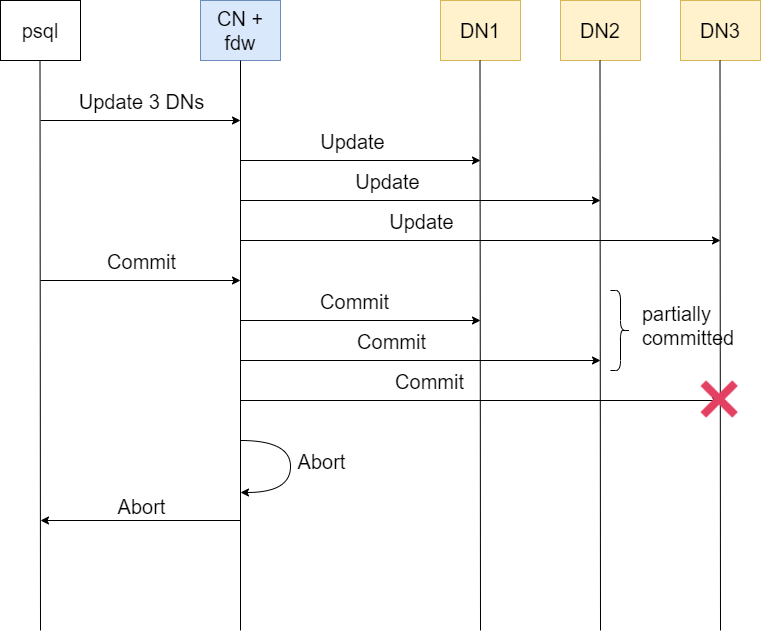
Introduction
On December 14-17, 2021, PostgresConf.CN & PGconf.Asia2021 (referred to as 2021 PG Asia Conference) was held online successfully and once again listed as a global gold standard conference on Postgresql.org! This conference was jointly organized by the China PostgreSQL Association, PostgresConf International Conference Organization,and PGConf.Asia Asian Community
About the Conference
Also known as the Asia’s largest open source relational database ecology conference
PostgresConf.CN and PGConf.Asia were hosted together as one conference online for the first time back in 2020. In 2021, both conferences joined forces again to deliver another successful conference that attracted record high numbers of PG enthusiasts from the world!
PostgresConf.CN is an annual conference held by the China PostgreSQL Association for PostgreSQL users and developers. It is also one of the conference series held by PostgresConf Organization. PostgreConf.CN 2019 took place in Beijing, it was very well attended by PostgreSQL users and community members across the globe.
PGCONF.Asia is also an annual PostgreSQL event that took place in Bali Indonesia in 2019, it was a continuation of the PGCONF.Asia event that took place in Tokyo, Japan in 2018. The first PGCONG.Asia conference took place in 2016 in Tokyo, this conference acts as a hub of PostgreSQL related development and technical discussion among PostgreSQL users and developers in the region as well as experts from around the globe.
Learn more about these conferences and the organizers from these resources:
This conference was sponsored by:
Platinum:
Golden:
Silver:
14 Conference Channels over 4 Days!
This conference was broadcast live with a record-high number of viewers streaming the conference events. It consists of a total of 14 live channels delivering speeches in Mandarin Chinese, English, Korean and Indonesian languages.
the conference gathered 101 technical presentations and more than 100 well-known experts and scholars around the world to provide a grand technical feast for all the participating PG enthusiasts.
- Guangnam Ni, Fellow of the Chinese Academy of Engineering
- Peng Liu, Vice chairman of China Open Source Software Promotion Alliance and researcher of the Chinese Academy of Sciences
- Xing Chunxiao, deputy director of the Information System Committee of the China Computer Federation
- Bruce Momjian, co-founder of PostgreSQL international community and vice president of EDB
- Peter Zaitsev, Founder and CEO of Percona
- Ding Zhiming, Director of the Spatiotemporal Data Science Research Center of the Chinese Academy of Sciences
- Experts from from HighGo, Alibaba, Tencent, Amazon, Kylin, Inspur, Ping An, Meichuang, SphereEx, Inspur Yunxi database, VMware Greenplum, Huawei, Ali cloud, ZTE…etc
- Professors from Peking University, Tsinghua University, Institute of Information Technology, Chinese Academy of Sciences, Shenzhen University, Zhengzhou University, Shandong Normal University, Suzhou University of Science and Technology and other academic and scientific research institutions
- And many, many more!
With the great support from these PostgreSQL communities, the conference was held with great success, which brought together the Chinese PG power, major Asian PG contributors and many PostgreSQL experts worldwide to build the largest PG ecosystem in Asia.
Conference Highlights
Opening Speech by Fellow Guangnan Ni

Guangnan Ni first expressed his warm congratulations to the holding of the PGConf.Asia 2021 Asia Conference, and greeted sincerely to the representatives of various countries and open source experts participating in the conference. He pointed out that open source is an important trend in the development of today’s world, and open source technology is profoundly changing the global digital economy and information industry pattern. The holding of this PG Asia Conference is of great significance to the development of the open source industry, the promotion of the open source movement and the popularization of open source culture in China, and the strengthening of international exchanges and cooperation.
Bruce Momjian

Bruce Momjian, as a core group member of the PG international community, has always been keen on sharing themes in the community. This time Bruce made a sharing based on the status quo of PG, project development challenges, competition challenges, and technical challenges, mainly emphasizing that the development process of the PG version has been adapting. Changes in the environment, continuous breakthroughs and innovations, such as SSD optimization, virtualization, containerization, and functional expansion of cloud environments have been completed in the face of technical challenges. For the future evolution of the PG version, it will continue to optimize and iterate on several aspects such as PG write amplification, TDE encryption, and horizontal scalability.
Peter Zaitsev

Mr. Peter Zaitsev, CEO of Percona, has been a guest at the PG Asia Conference for the second time. This time Peter brought us a speech of “State of Open Source Databases”, mainly from cloud computing, PG peripheral ecology, DaaS and K8S. This aspect expresses the openness and flexibility of PG, which enables PG and the evolution of the technical architecture to be better integrated, promote mutual development, and meet the needs of different business scenarios. He said that Percona, which has been engaged in open source database services for many years, loves to embrace PG and make innovations based on PG to bring more value to customers.
Chunxiao Xing
Professor Xing Chunxiao, deputy dean of the Institute of Information Technology of Tsinghua University and deputy director of the Information System Committee of the China Computer Federation, shared with us the most popular topics of “metaverse”, blockchain, and data lake, emphasizing that data management is a popular technology development Only the continuous evolution and iteration of database management software can better provide support for cutting-edge technologies and make our lives more meaningful.
Zhiming Ding

The ivorySQL project is a PG open source derivative project with a broad ecological foundation and Chinese characteristics. Its purpose is to develop community collaboration among Chinese developers and allow engineers to create greater personal and social value.
The session was presented by Professor Ding Zhiming, an early promoter of research practice in the domestic PG field, the new president of the China PG branch, and director of the Center for Space-Time Data Science (STDMS) of the Chinese Academy of Sciences. Their system completely expounds the necessity and realization idea of “PostgreSQL database software + Chinese characteristics”, the positioning, characteristics and operation mode of the ivorySQL project and community. Through the launch event, the project was officially known to the majority of PG practitioners in China.
The launch of IvorySQL attracted many domestic PG enthusiasts, and they have provided suggestions and opinions to make the project better. We feel very thankful for their effort into this new project. In the mean time, please check out the project’s official website at www.ivorysql.org for the latest developments.
Xiaojun Zheng

Xiaojun Zheng, Chief Scientist of HighGo, presented “Highgo peer-to-peer service cluster database”.
Mr. Zheng first gave a systematic overview of the definition of database cluster, and then explained the concept and implementation of “peer-to-peer service cluster” in a more generalized manner. Finally, Mr. Zheng led everyone to experience Higao’s Peer-to-peer service cluster database environment. Through this practical demonstration, we have brought you a new idea and method for realizing peer-to-peer service clustering. Architects and product managers who pay attention to the PostgreSQL database, I believe they can gain new product inspiration from it.
Jian Feng

Director Feng first introduced the two major product lines of K1 Power and their respective market opportunities, advantages, and application scenarios. He then demonstrated the business value of K1 Power’s advanced virtualization features to PostgreSQL database in four aspects, and elaborated on running under K1 Power Linux. The best practices of the PostgreSQL database and the uniqueness of the x86 CPU. Finally, Director Feng introduced the PowerFans community on Github https://github.com/powerfans/. This PowerFan community can be said to be the king of technical feasts. In addition to providing the above best practices, it also provides open-source software binary packages, useful tools and documentation, etc. This PowerFans community provides database enthusiasts with great convenience to use the Power server platform, such as: PostgreSQL under the PowerLinux platform and you no longer need to make RPM packages yourself, Inspur commercial machines are ready for you!
Grant Zhou - The Launch of IvorySQL Open Source Project

This conference specially invited the well-known domestic database solution supplier, HighGo Database, to jointly organize and launch the HighGo database sub-forum. Jichao Ma, the pre-sales director of HighGo Software, presented “Highgo Database New Features”, and introduced some new features and functions of HighGo Database related to high availability.
Grant Zhou, head of the IvorySQL open source community presented “IvorySQL-an Oracle compatible open source PostgreSQL database”, and introduced an Oracle-compatible open source PostgreSQL database ivorySQL.
KaiGai Kohei

KaiGai Kohei has been a contributor of PostgreSQL and Linux kernel over 15 years. He presented a speech called “GPU revision of PostGIS” that introduces an extension called “PG-Storm” to pull resource from GPU for analytic SQL workloads.
Takeshi MISHIMA

Takeshi MISHIMA is a Ph.D in engineering principle of SRA OSS, Inc. He presented a speech called “A Middleware to Synchronize Multiple Instances in a PostgreSQL Cluster” that introduced a middle ware called “Pangea” to provide better performance in clustering synchronization by load balancing SELECT queries
Paul Brebner

Paul Brebneris the Technology Evangelist at Instaclustr. He’s been learning new scalable open source technologies, solving realistic problems, and building applications, and blogging about Apache Cassandra, Apache Kafka and of course PostgreSQL! He presented a speech called “Change Data Capture (CDC) With Kafka Connect and the Debezium PostgreSQL Source Connector” to introduce the “Debezium PostgreSQL Connector”, and explain how it can make the elephant (PostgreSQL) to be as fast as a cheetah (Kafka) such that the system becomes more change-aware and flexible.
Michael Christofides

Michael Christofides is the Co-founder of pgMustard who presented a speech called “A beginners guide to EXPLAIN ANALYZE” to give a beginner friendly introduction to EXPLAIN vs EXPLAIN ANALYZE.
Bohan Zhang

Bohan Zhang is the co-founder of OtterTune who presented a speech called “Ottertune: automatic database optimization using machine learning” which talks about how the database group of Carnegie Mellon University uses machine learning to automatically tune and improve database systems.
Ibrar Ahmed

Ibrar Ahmed is a Senior Software Architect in Percona LLC who has vast experience in software design and development with PostgreSQL. He presented a speech “A Deep Dive into PostgreSQL Indexing” and share some useful strategies how to take fully advantage of different index types that can be extremely useful for systems developers. He also emphasized that not all index types are appropirate for all circumstances; sometimes, inproper use of index can lower database performance.
Karel van der Walt

Karel van der Walt is the principle of MentalArrow who presented a speech called “Modularizing computation via Common Table Expressions (CTEs)”, which discusses a topic to add modularized computation on top of the existing building blocks of CTEs to improve readability and testability
Yugo Nagata

Yugo Nagata is a software engineer and chief scientist at SRA OSS, Japan. He is a specialist in database engineering who has great interest in PostgreSQL theories and internals. He presented a speech called “PostgreSQL Internals and Incremental View Maintenance Implementation” to share a very interesting technique to update materialzied views rapidly (instead of the old REFRESH MATERIALIZED VIEW). He also explaied the internal workings of materialized views amd shared the status of his current patch proposal of “Incremental View Maintenance” feature to the PostgreSQL community.
Cary Huang

Cary Huang is a senior software developer of HornetLab Technology in Canada. He presented a speech called “The principles behind TLS and How it protects PG” to discuss the TLS protocol in details and explain how it is the most commonly used but the least understood security protocol today.
Muhammad Usama

Muhammad Usama is a database architect of HornetLab Technology and a major contributor to Pgpool-II. He presented a speech called “PostgreSQL HA with Pgpool-II and whats been happening in Pgpool-II lately….” to discuss the roadmap of core features of Pgpool-II with strong emphasis on High Availability (HA), in which Muhammad believed is the most critical aspect of any enterprise application.
Asif Rehman

Asif Rehman is a senior software engineer at HornetLab Technology and he presented a speech called “PostgreSQL Replication” which explained the purpose of replication and discussed all types of replication methods with their pros and cons in different scenarios.
Seoul Sub-Forum

In the Seoul sub-forum, four Korean PostgreSQL user group members gave speeches, namely Ioseph Kim, Jaegeun Yu, Daniel Lee, and Lee Jiho.
Ioseph Kim is a contributor to PostgreSQL11 and PostgreSQL12 and translated the PostgreSQL Korean documentation. The topic of his speech was “Peculiar SQL with PostgreSQL for application developer”. In this speech, Loseph Kim talked about the syntax of PostgreSQL’s Lateral Joins, distinct on… etc. He also introduced the new features of PostgreSQL14.
Jaegeun Yu has more than 3 years of experience as a PostgreSQL DBA. The topic of his speech is “Porting from Oracle UDF and Optimization”. In this speech, Jaegeun Yu talks about the basic principles of function optimization and shows how to write PostgreSQL functions efficiently while porting, and illustrate the migration process with examples.
Daniel Lee brought you a speech “Citus high-availability environment deployment based on Patroni”. In this speech, Daniel Lee introduced the high availability technology solution of Citus, and actually demonstrated the steps to build a Citus HA environment based on Patroni.
Lee Jiho is the head of the department at insignal in Korea, and has more than 20 years of experience in using PostgreSQL. Lee Jiho brought a speech “Database configuration and migration and index clustering around clusters in PostgreSQL”. In this speech, Lee Jiho introduced the changes and upgrades of Cluster, table clustering … etc.
Jakarta Sub-Forum

In Jakarta sub-forum, CEO-Julyanto Sutandang and CTO-Lucky Haryadi from Equnix Business Solutions brought 3 speeches in Indonesian.
Equunix Business Solutions’ CEO-Julyanto Sutandang brought 2 speeches on “Active active PostgreSQL Do We Really Need It” and “In-memory Database, Is It Really Faster?”, Equunix Business Solutions CTO-Lucky Haryadi’s speech topic is “oes HA Can Help You Balance Your Load”. As a technology company with strong influence in the field of PostgreSQL and Linux in Southeast Asia, the speech brought by Equnix Business Solutions is a perfect combination of practice and theory.
The successful landing of this Jakarta sub-forum has greatly promoted the dissemination and development of PostgreSQL database technology in Indonesia and even Southeast Asia.
Special Thanks To