

1. Overview
Table partitioning is introduced after Postgres version 9.4 that provides several performance improvement under extreme loads. Partitioning refers to splitting one logically large table into smaller pieces, which in turn distribute heavy loads across smaller pieces (also known as partitions).
There are several ways to define a partition table, such as declarative partitioning and partitioning by inheritance. In this article we will focus on a simple form of declarative partitioning by value range.
Later in this article, we will discuss how we can define a TRIGGER to work with a FUNCTION to make table updates more dynamic.
2. Creating a Table Partition by Range
Let’s define a use case. Say we are a world famous IT consulting company and there is a database table called salesman_performance, which contains all the sales personnel world wide and their lifetime revenue of sales. Technically it is possible to have one table containing all sales personnel in the world but as entries get much larger, the query performance may be greatly reduced.
Here, we would like to create 7 partitions, representing 7 different levels of sales (or ranks) like so:
CREATE TABLE salesman_performance ( |
Please note that, we have to specify that it is a partition table by using keyword “PARTITION BY RANGE”. It is not possible to alter a already created table and make it a partition table.
Now, let’s create 7 partitions based on revenue performance:
CREATE TABLE salesman_performance_chief PARTITION OF salesman_performance |
Let’s insert some values into “salesman_performace” table with different users having different revenue performance:
INSERT INTO salesman_performance VALUES( 1, 'Cary', 'Huang', 4458375.34, '2019-09-20 16:00:00'); |
Postgres will automatically distribute queries to the respective partition based on revenue range.
You may run the \d+ command to see the table and its partitions
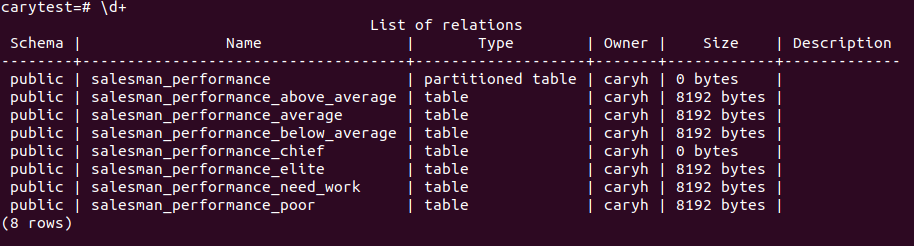
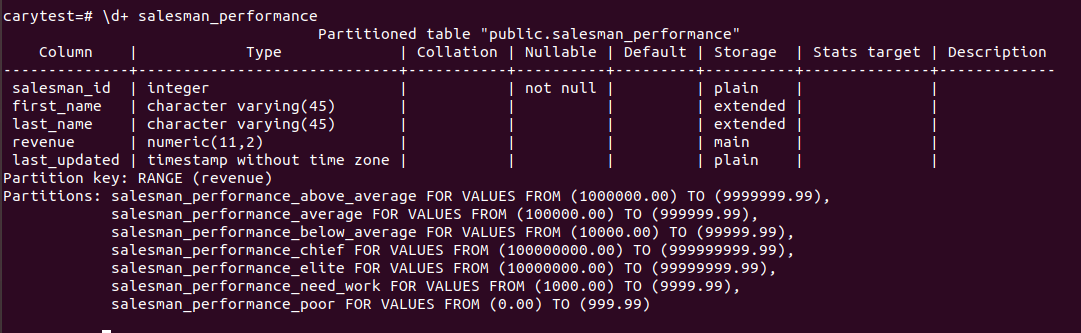
or examine just salesman_performance, which shows partition key and range
\d+ salesman-performance |
we can also use EXPLAIN ANALYZE query to see the query plan PG system makes to scan each partition. In the plan, it indicates how many rows of records exist in each partition
EXPLAIN ANALYZE SELECT * FROM salesman_performance; |
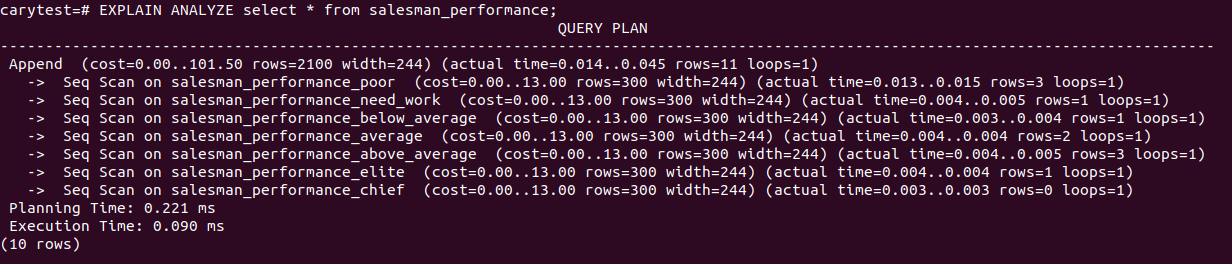
There you have it. This ia a very basic partition table that distributes data by value range.
One of the advantages of using partition table is that bulk loads and deletes can be done simply by adding or removing partitions (DROP TABLE). This is much faster and can entirely avoid VACUUM overhead caused by DELETE
When you make a update to an entry. Say salesman_id 1 has reached the “Chief” level of sales rank from “Above Average” rank
UPDATE salesman_performance SET revenue = 445837555.34 where salesman_id=1; |
You will see that Postgres automatically put salesman_id 1 into the “salesman_performance_chief” partition and removes from “salesman_performance_above_average”
3. Delete and Detach Partition
A partition can be deleted completely simply by the “DROP TABLE [partition name]” command. This may not be desirable in some use cases.
The more recommended approach is to use “DETACH PARTITION” queries, which removes the partition relationship but preserves the data.
ALTER TABLE salesman_performance DETACH PARTITION salesman_performance_chief; |
If a partition range is missing, and the subsequent insertion has a range that no other partitions contain, the insertion will fail.
INSERT INTO salesman_performance VALUES( 12, 'New', 'User', 755837555.34, current_timestamp); |
If we add back the partition for the missing range, then the above insertion will work:
ALTER TABLE salesman_performance ATTACH PARTITION salesman_performance_chief |
4. Create Function Using Plpgsql and Define a Trigger
In this section, we will use an example of subscriber and coupon code redemption to illustrate the use of Plpgsql function and a trigger to correctly manage the distribution of available coupon codes.
First we will have a table called “subscriber”, which store a list of users and a table called “coupon”, which stores a list of available coupons.
CREATE TABLE subscriber ( |
Let’s insert some records to the above tables:
INSERT INTO subscriber (sub_id, first_name, last_name, last_updated) VALUES(1,'Cary','Huang',current_timestamp); |
The tables now look like: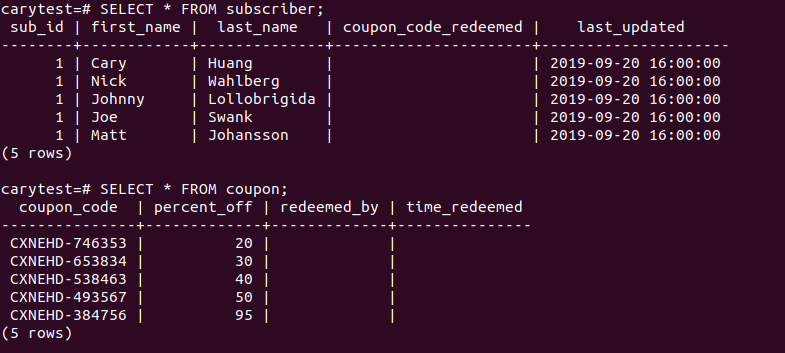
Say one subscriber redeems a coupon code, we would need a FUNCTION to check if the redeemed coupon code is valid (ie. Exists in coupon table). If valid, we will update the subscriber table with the coupon code redeemed and at the same time update the coupon table to indicate which subscriber redeemed the coupon and at what time.
CREATE OR REPLACE FUNCTION redeem_coupon() RETURNS trigger AS $redeem_coupon$ |
we need to define a TRIGGER, which is invoked BEFORE UPDATE, to check the validity of a given coupon code.
CREATE TRIGGER redeem_coupon_trigger |
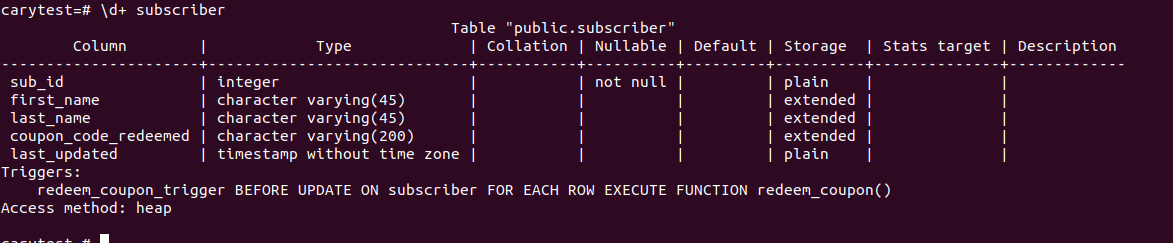
\d+ subscriber should look like this:
Let’s have some users redeem invalid coupon codes and as expected, an exception will be raised if coupon code is not valid.
UPDATE subscriber set coupon_code_redeemed='12345678' where first_name='Cary'; |
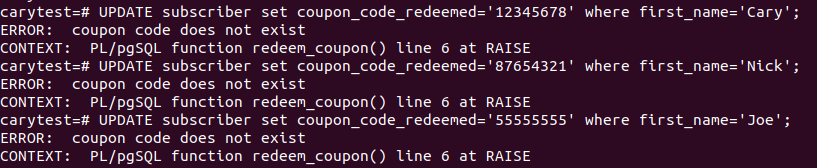
Let’s correct the above and redeem only the valid coupon codes and there should not be any error.
UPDATE subscriber set coupon_code_redeemed='CXNEHD-493567' where first_name='Cary'; |

Now both table should look like this, and now both table have information cross-related.
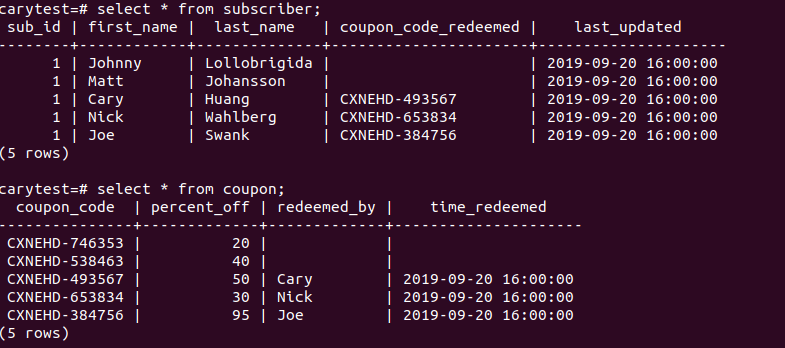
And there you have it, a basic trigger function executed before each update.
5. Summary
With the support of partitioned table defined by value range, we are able to define a condition for postgres to automatically split the load of a very large table across many smaller partitions. This has a lot of benefits in terms of performance boost and more efficient data management.
Having postgres FUNCTION and TRIGGER working together as a duo, we are able to make general queries and updates more dynamic and automatic to achieve more complex operations. As some of the complex logics can be defined and handled as FUNCTION, which is then invoked at appropriate moment defined by TRIGGER, the application integrated to Postgres will have much less logics to implement.



