
1. Introduction
PostgreSQL and MongoDB are two popular open source relational (SQL) and non-relational (NoSQL) databases available today. Both are maintained by groups of very experienced development teams globally and are widely used in many popular industries for adminitration and analytical purposes. MongoDB is a NoSQL Document-oriented Database which stores the data in form of key-value pairs expressed in JSON or BSON; it provides high performance and scalability along with data modelling and data management of huge sets of data in an enterprise application. PostgreSQL is a SQL database designed to handle a range of workloads in many applications supporting many concurrent users; it is a feature-rich database with high extensibility, which allows users to create custom plugins, extensions, data types, common table expressions to expand existing features
I have recently been involved in the development of a MongoDB Decoder Plugin for PostgreSQL, which can be paired with a logical replication slot to publish WAL changes to a subscriber in a format that MongoDB can understand. Basically, we would like to enable logical replication between MongoDB (as subscriber) and PostgreSQL (as publisher) in an automatic fashion. Since both databases are very different in nature, physical replication of WAL files is not applicable in this case. The logical replication supported by PostgreSQL is a method of replicating data objects changes based on replication identity (usually a primary key) and it would be the ideal choice for this purpose as it is designed to allow sharing the object changes between PostgreSQL and multiple other databases. The MongoDB Decoder Plugin will play a very important role as it is directly responsible for producing a series of WAL changes in a format that MongoDB can understand (ie. Javascript and JSON).
In this blog, I would like to share some of my initial research and design approach towards the development of MongoDB Decoder Plugin.
2. Architecture
Since it is not possible yet to establish a direct logical replication connection between PostgreSQL and MongoDB due to two very different implementations, some kind of software application is ideally required to act as a bridge between PostgreSQL and MongoDB to manage the subscription and publication. As you can see in the image below, the MongoDB Decoder Plugin associated with a logical replication slot and the bridge software application are required to achieve a fully automated replication setup.
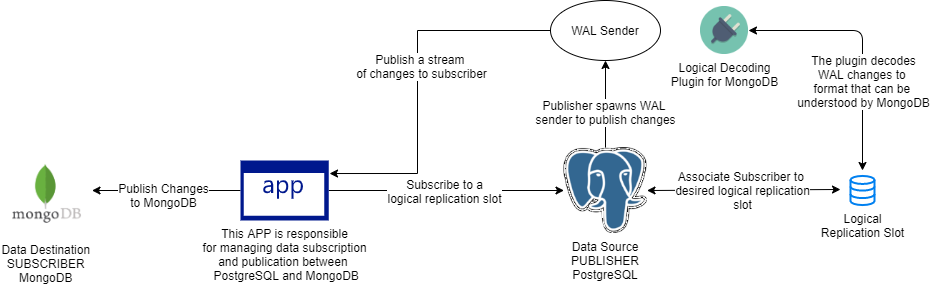
Unfortunately, the bridge application does not exist yet, but we do have a plan to develop such application in near future. So, for now, we will not be able to have a fully automated logical replication setup. Fortunately, we can utilize the existing pg_recvlogical front end tool to act as a subscriber of database changes and publish these changes to MongoDb in the form of output file, as illustrated below.
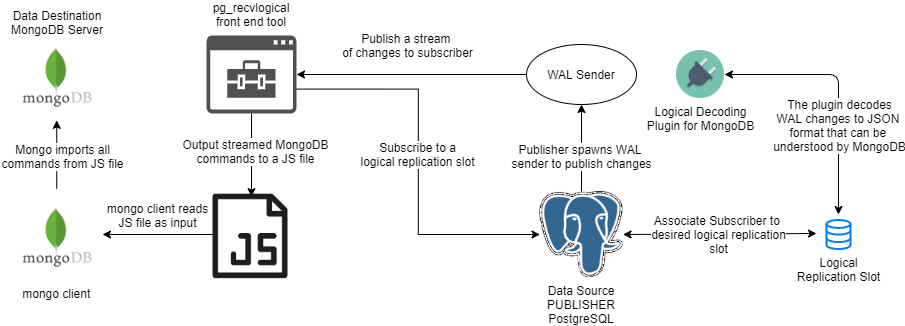
With this setup, we are able to verify the correctness of the MongoDB Decoder Plugin output against a running MongoDB in a semi-automatic fashion.
3. Plugin Usage
Based on the second architecture drawing above without the special bridge application, we expect the plugin to be used in similar way as normal logical decoding setup. The Mongodb Decoder Plugin is named wal2mongo as of now and the following examples show the envisioned procedures to make use of such plugin and replicate data changes to a MongoDB instance.
First, we will have to build and install wal2mongo in the contrib source folder and start a PostgreSQL cluster with the following parameters in postgresql.conf. The wal_level = logical tells PostgreSQL that the replication should be done logically rather than physically (wal_level = replica). Since we are setting up replication between 2 very different database systems in nature (PostgreSQL vs MongoDB), physical replication is not possible. All the table changes will be replicated to MongoDB in the form of logical commands. max_wal_senders = 10 limits the maximum number of wal_sender proccesses that can be forked to publish changes to subscriber. The default value is 10, and is sufficient for our setup.
wal_level = logical |
On a psql client session, we create a new logical replication slot and associate it to the MongoDB logical decoding plugin. Replication slot is an important utility mechanism in logical replication and this blog from 2ndQuadrant has really good explaination of its purpose: (https://www.2ndquadrant.com/en/blog/postgresql-9-4-slots/)
$ SELECT * FROM pg_create_logical_replication_slot('mongo_slot', 'wal2mongo'); |
where mongo_slot is the name of the new logical replication slot and wal2mongo is the name of the logical decoding plugin that you have previously installed in the contrib folder. We can check the created replication slot with this command:
$ SELECT * FROM pg_replication_slots; |
At this point, the PostgreSQL instance will be tracking the changes done to the database. We can verify this by creating a table, inserting or deleting some values and checking the change with the command:
$ SELECT * FROM pg_logical_slot_get_changes('mongo_slot', NULL, NULL); |
Alternatively, one can use pg_recvlogical front end tool to subscribe to the created replication slot, automatically receives streams of changes in MongoDB format and outputs the changes to a file.
$ pg_recvlogical --slot mongo_slot --start -f mongodb.js |
Once initiated, pg_recvlogical will continuously stream database changes from the publisher and output the changes in MongoDB format and in mongodb.js as output file. It will continue to stream the changes until user manually terminates or the publisher has shutdown. This file can then be loaded to MongoDB using the Mongo client tool like this:
$ mongo < mongodb.js |
where the mongodb.js file contains:
use mydb; |
4. Terminology
Both databases use different terminologies to describe the data storage. Before we can replicate the changes of PostgreSQL objects and translate them to MongoDB equivalent, it is important to gain clear understanding of the terminologies used on both databases. The table below is our initial terminology mappings:
| PostgreSQL Terms | MongoDB Terms | MongoDB Description |
|---|---|---|
| Database | Database | A physical container for collections |
| Table | Collection | A grouping of MongoDB documents, do not enforce a schema |
| Row | Document | A record in a MongoDB collection, can have difference fields within a collection |
| Column | Field | A name-value pair in a document |
| Index | Index | A data structure that optimizes queries |
| Primary Key | Primary Key | A record’s unique immutable identified. The _id field holds a document’s primary key which is usually a BSON ObjectID |
| Transaction | Transaction | Multi-document transactions are atomic and available in v4.2 |
5. Supported Change Operations
Our initial design of the MongoDB Decoder Plugin is to support database changes caused by clauses “INSERT”, “UPDATE” and “DELETE”, with future support of “TRUNCATE”, and “DROP”. These are few of the most common SQL commands used to alter the contents of the database and they serve as a good starting point. To be able to replicate changes caused by these commands, it is important that the table is created with one or more primary keys. In fact, defining a primary key is required for logical replication to work properly because it serves as replication identity so the PostgreSQL can accurately track a table change properly. For example, if a row is deleted from a table that does not have a primary key defined, the logical replication process will only detect that there has been a delete event, but it will not be able to figure out which row is deleted. This is not what we want. The following is some basic examples of the SQL change commands and their previsioned outputs:
$ BEGIN; |
The simple SQL commands above can be translated into the following MongoDB commands. This is a simple example to showcase the potential input and output from the plugin and we will introduce more blogs in the near future as the development progresses further to show case some more advanced cases.
db.table1.insert({“a”: 1, “b”: “Cary”, “c”: “2020-02-01”}) |
6. Atomicity and Transactions
A write operation in MongoDB is atomic on the level of a single document, and since MongoDB v4.0, multi-document transaction control is supported to ensure the atomicity of multi-document write operations. For this reason, the MongoDB Deocoder Plugin shall support 2 output modes, normal and transaction mode.
In normal mode, all the PostgreSQL changes will be translated to MongoDB equivalent without considering transactions. In other words, users cannot tell from the output if these changes are issued by the same or different transactions. The output can be fed directly to MongoDB, which can gurantee certain level of atomicity involving the same document
Since MongoDB v4.0, there is a support for multi-document transaction mechanism, which acts similarly to the transaction control in PostgreSQL. Consider a normal insert operation like this with transaction ID = 500 within database named “mydb” and having cluster_name = “mycluster” configured in postgresql.conf:
$ BEGIN; |
In normal output mode, the plugin will generate:
use mydb; |
In transaction output mode, the plugin will generate:
session500_mycluster = db.getMongo().startSession(); |
Please note that the session variable used in the MongoDB output is composed of the word session concatenated with the transaction ID and the cluster name. This is to gurantee that the variable name will stay unique when multiple PostgrSQL databases are publishing using the same plugin towards a single MongoDB instance. The cluster_name is a configurable parameter in postgresql.conf that is used to uniquely identify the PG cluster.
The user has to choose the desired output modes between normal and transaction depending on the version of the MongoDB instance. MongoDB versions before v4.0 do not support multi-document transaction mechanism so user will have to stick with the normal output mode. MongoDB versions after v4.0 have transaction mechanism supported and thus user can use either normal or transaction output mode. Generally, transaction output mode is recommended to be used when there are multiple PostgreSQL publishers in the network publishing changes to a single MongoDB instance.
7. Data Translation
PostgreSQL supports far more data types than those supported by MongoDB, so some of the similar data types will be treated as one type before publishing to MongoDB. Using the same database name, transaction ID and cluster name in previous section, the table below shows some of the popular data types and their MongoDB transaltions.
| PostgreSQL Datatype | MongoDB Datatype | Normal Output | Transaction Output |
|---|---|---|---|
| smallint integer bigint numeric | integer | db.table1.insert({“a”:1}) | session500_mycluster.getDatabase(“mydb”).table1.insert(“db”).table1.insert({“a”: 1}) |
| character character varying text json xml composite default other types | string | db.table1.insert({“a”: “string_value”}) | session500_mycluster.getDatabase(“mydb”).table1.insert({“a”: “string_value”}) |
| boolean | boolean | db.table1.insert({“a”:true}) | session500_mycluster.getDatabase(“mydb”).table1.insert({“a”: true}) |
| double precision real serial arbitrary precision | double | db.table1.insert({“a”:34.56}) | session500_mycluster.getDatabase(“mydb”).table1.insert({“a”: 34.56}) |
| interval timestamp data time with timezone time without timezone | timestamp | db.table1.insert({“a”: new Date(“2020-02-25T19:33:10Z”)}) db.table1.insert({“a”: new Date(“2020-02-25T19:33:10+06:00”)}) | session500_mycluster.getDatabase(“mydb”).table1.insert({“a”:new Date(“2020-02-25T19:33:10Z”)}) session500_mycluster.getDatabase(“mydb”).table1.insert({“a”:new Date(“2020-02-25T19:33:10+06:00”)}) |
| hex bytea bytea UUID | binary data | db.table1.insert({“a”: UUID(“123e4567-e89b-12d3-a456-426655440000”)}) db.table1.insert({“a”:HexData(0,”feffc2”)}) | session500_mycluster.getDatabase(“mydb”).table1.insert({“a”:UUID(“123e4567-e89b-12d3-a456-426655440000”)}) session500_mycluster.getDatabase(“mydb”).table1.insert({“a”:HexData(0,”feffc2”)}) |
| array | array | db.table1.insert({ a: [ 1, 2, 3, 4, 5 ] } ) db.table1.insert({ a: [ “abc”, “def”, “ged”, “aaa”, “xxx” ] } ) | session500_mycluster.getDatabase(“mydb”).table1.insert( { a: [ 1, 2, 3, 4, 5 ] } ) session500_mycluster.getDatabase(“mydb”).table1.insert( { a: [ “abc”, “def”, “ged”, “aaa”, “xxx” ] } ) |
8. Conclusion
MongoDB has gained a lot of popularity in recent years for its ease of development and scaling and is ideal database for data analytic purposes. Having the support to replicate data from multiple PostgreSQL clusters to a single MongoDB instance can bring a lot of value to industries focusing on data analytics and business intelligence. Building a compatible MongoDB Decoder Plugin for PostgreSQL is the first step for us and we will be sharing more information as development progresses further. The wal2mongo project is at WIP/POC stage and current work can be found here: https://github.com/HighgoSoftware/wal2mongo.



