
1. Introduction
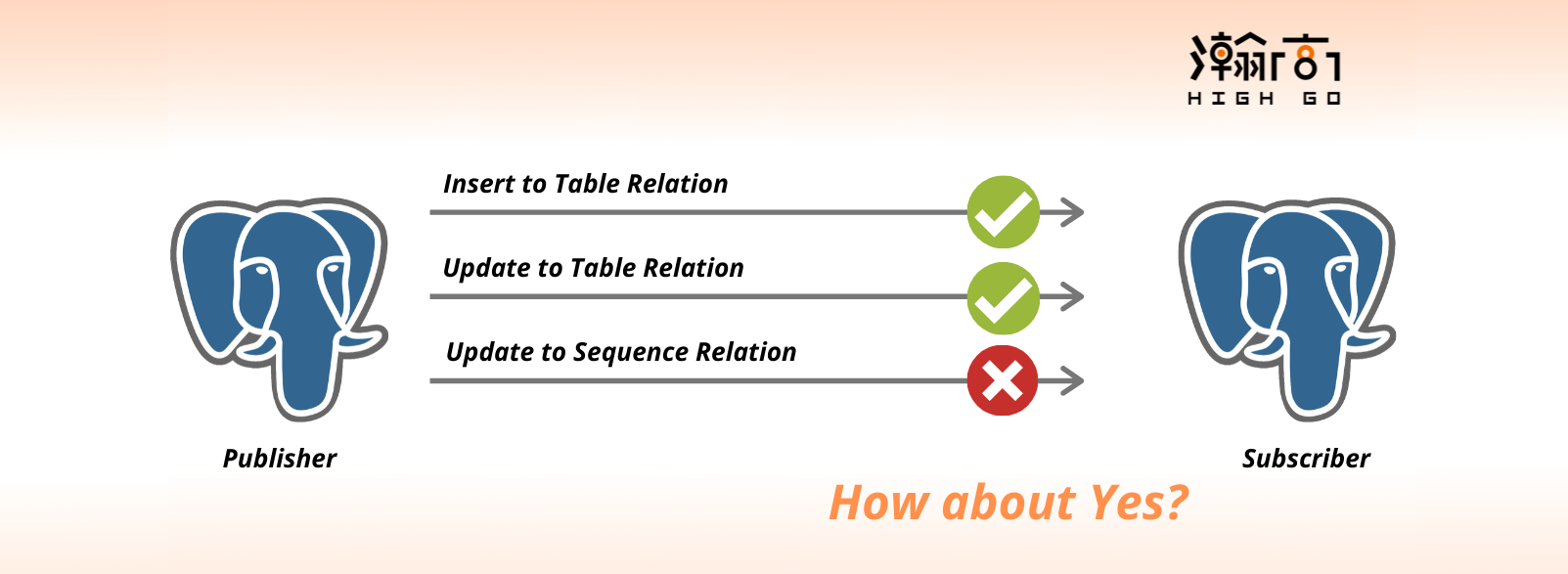
I have noticed that there is a page on the offical PostgreSQL documentation (https://www.postgresql.org/docs/current/logical-replication-restrictions.html) that states several restrictions to the current logical replication design. One of the restrictions is about sequence relation type where any changes associated with a sequence relation type is not logically replicated to the subscriber or to the decoding plugin. This is an interesting restriction and I took the initiative to look into this restriction further and evaluate if it is possible to have it supported. I have consulted several senior members in the PostgreSQL communitiy and got some interesting responses from them. In this blog, I will share my current work in the area of supporting sequence replication.
2. What is a Sequence?
Sequence is a special type of relation that is used as a number generator manager, which allows an user to request the next number from the sequence, reset the current value, change the size of increment (or decrement) and perform several other configurations that suit their needs. A sequence is automatically created when an user creates a regular table that contains a column of type SERIAL. Alternatively, a sequence can also be created manually by using the CREATE SEQUENCE seqname; command. A sequence is similar to a regular table except that it can only contain 1 single row, is created with a special schema by default that contains several control parameters for managing the number generation and user cannot use UPDATE clause on a sequence. SQL functions such as nextval(), currval(), setval() and ALTER commands are the proper methods of accessing or modifying sequence data.
3. Why is Sequence not Replicated in Current Design?
This is the question I ask myself and the PostgreSQL community for several times and I have received several interesting responses to this question. Like a regular table, sequence also emits a WAL update upon a change to the sequence value but with a major difference. Instead of emitting a WAL update at every nextval() call, sequence actually does this at every 32 increments and it logs a future value 32 increments after instead of current value. Doing WAL logging every 32 increments adds a significant gain in performance according to a benchmark report shared by the community. For example, if current sequence value is 50 with increment of 5, the value that is written to WAL record will be 210, because ( 50 + (32x5) = 210). This also means that in an events of a crash, some sequence values will be lost. Since sequence does not guarentee free of gap and is not part of user data, such a sequence loss is generally ok.
Logical replication is designed to track the WAL changes and report to subscribers about the current states and values. It would be quite contradicting to replicate sequence because the current sequence value does not equal to the value stored in the WAL. The subscriber in the sequence case will receive a value that is 32 increments in the future.
Another response I have got is that the implementation of sequence intermixed a bunch of transactional and non-transactional states in a very messy way, thus making it difficult to achieve sensible behaviour for logical decoding.
4. Can Sequence Relation be Logically Replicated?
In the current PostgreSQL logical replication architecture, yes it is possible to have a patch to replicate changes to a sequence relation. Before we dive in further, we have to understand what the benefit would be if we were able to replicate a sequence. In the current design, an user is able to set up a PostgreSQL publisher and subscriber to replicate a table that could be associated with a sequence if it has a column of data type SERIAL. The values of the table will be copied to the subscriber of course, but the state of sequence will not. In the case of a failover, the subscriber may not be able to insert more data to the table because SERIAL data is often declared as PRIMARY KEY and it could use an unexpected sequence value that conflicts with existing records. To remedy this, PostgreSQL documentation suggests manually copying over the sequence values or use utility such as pg_dump to do the copying. I believe it is the biggest benefit if sequence relation can be replicated such that in a fail over case, the user is no longer required to manually synchronize the sequence states.
5. Where to Add the Sequence Replication Support?
Logical replication actually has 2 routes, first is via the logical decoding plugin to a third party subscriber, second is between a PostgreSQL publisher and subscriber. Both routes are achieved differently in multiple source files but both do invoke the same common modules in the replication module in the PostgreSQL source repository. This section will describe briefly these common modules
5.1 Define a New Change Type
Since sequence change has some fundamental difference between the usual changes caused by INSERT, UPDATE or DELETE, it is better to define a new change type for sequence in reorderbuffer.h first:
enum ReorderBufferChangeType |
Create a new struct that stores the context data for sequence changes within the ReorderBufferChange union
typedef struct ReorderBufferChange |
As you can see, for sequence change, we will only have the newtuple that represents the new sequence value. Old tuple is not needed here.
5.2 The Logical Decoder Module (src/backend/replication/logical/decode.c)
This module decodes WAL records for the purpose of logical decoding, utilizes snapbuild module to build a fitting catalog snapshot and passes information to the reorderbuffer module for properly decoding the changes.
For every WAL log read, the handle will be passed to LogicalDecodingProcessRecord for further decoding. As you can see for the type RM_SEQ_ID, there is no dedicated decoding function invoked. We should create a dedicated decoding function called DecodeSequence and update the switch statement such that the sequence type will use this decoding method.
void |
Now, we shall define the DecodeSequence function to actually do the decoding. Comments are embedded in the below code block to explain what each line is doing briefly.
static void |
The above will call a new function DecodeSeqTuple to actually turn raw tuple data into a ReorderBufferTupleBuf which is needed in reorderbuffer module. This function tries to break down each section of the WAL (written by sequence.c) into a ReorderBufferTupleBuf.
static void |
5.3 The Reorder Buffer Module (src/backend/replication/reorderbuffer.c)
reorderbuffer module receives transaction records in the order they are written to the WAL and is primarily responsible for reassembling and passing them to the logical decoding plugin (test_decoding for example) with individual changes. The ReorderBufferCommit is the last function before the change is passed down to the logical decoding plugin by calling the begin, change and commit callback handlers. This is where we will add a new logics to pass a sequence change.
void |
Once the decoding plugin receives a change of type REORDER_BUFFER_CHANGE_SEQUENCE, it will need to handle it and look up the proper change context to get the tuple information
static void |
6. Conclusion
We have discussed about the current implementation of logical decoding and some potential reasons why sequence is not supported in PostgreSQL logical replication. We have also gone through some important source files that could be updated to allow sequence replication. In the above approach, whenever the sequence module emits a WAL update, (which is a future value 32 increments later as discussed previously), the logical decoding plugin will receive this same future value, which is in fact different from the actual sequence value currently. This can be justified if we think about the purpose of sequence replication for a second, which is useful in fail over cases. With this future sequence value, the subsequent data insersions will be able to continue starting from this future sequence value.



