
1. Introduction
PostgreSQL backend is a collection of processes forked from the main process called Postmaster. Each forked process has different roles and responsibilities in the backend. This article describes the responsibility of core backend processes that power the PostgreSQL system as we know it today. The overall PostgreSQL backend architecture can be illustrated by the image below:
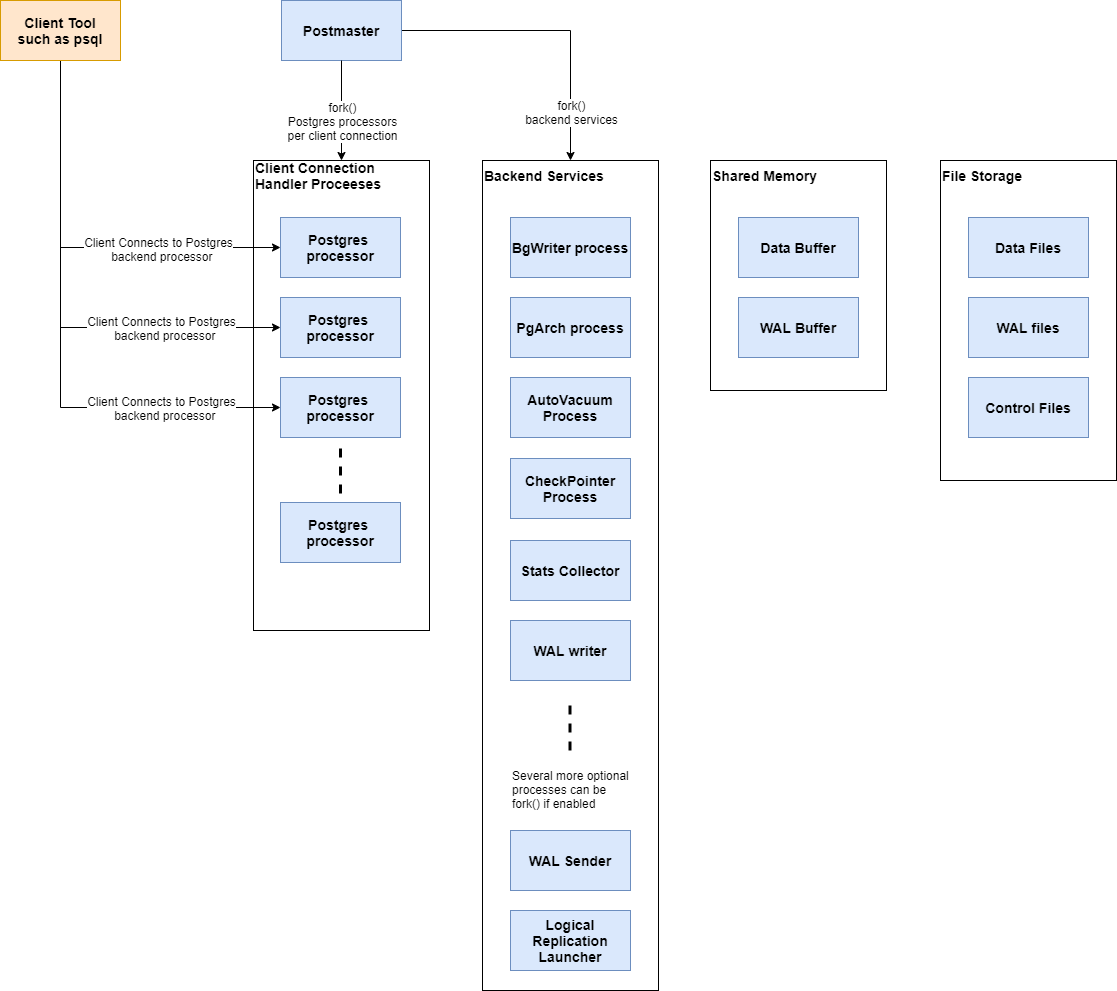
Postmaster is the first process to be started who has control of all the backend processes and is responsible for accepting and closing the database connections. At start up, the postmaster forks several backend processes that are intended to process different aspects of backend tasks, which we will be covering in this blog. When a user initiates a connection to the PostgreSQL database, the client process will send an authentication message to the Postmaster main process. The Postmaster main process authenticates the user according to the authentication methods configured and will fork a new session to provide service to this user only if the user passes authentication.
2. BgWriter (Background Writer) Process
The BgWriter process is a process that writes dirty pages in shared memory to disk. It has two functions: one is to periodically flush out the dirty data from the memory buffer to the disk to reduce the blocking during the query; the other is that the PG needs to write out all the dirty pages to the disk during the regular checkpoint. By BgWriter Writing out some dirty pages in advance, it can reduce the IO operations to be performed when setting checkpoints (A type of database recovery technology), so that the system’s IO load tends to be stable. BgWriter is a process added after PostgreSQL v8.0 and it has a dedicated section in postgresql.conf to configure its behavior.
# - Background Writer - |
bgwriter_delay:
The time interval between two consecutive flush data in the backgroud writer process. The default value is 200, and the unit is milliseconds.bgwriter_lru_maxpages:
The maximum amount of data written by the backgroud writer process at a time. The default value is 100, in units of buffers. If the amount of dirty data is less than this value, the write operation is all completed by the backgroud writer process; conversely, if it is greater than this value, the greater part will be completed by the server process process. When the value is set to 0, it means that the backgroud writer writing process is disabled, and it is completely completed by the server process; when it is set to -1, it means that all dirty data is done by the backgroud writer. (Checkpoint operations are not included here)bgwriter_lru_multiplier:
This parameter indicates the number of data blocks written to the disk each time, of course, the value must be less than bgwriter_lru_maxpages. If the setting is too small, the amount of dirty data that needs to be written is greater than the amount of data written each time, so the remaining work that needs to be written to the disk needs to be completed by the server process process, which will reduce performance; if the value configuration is too large, the amount of dirty data written More than the number of buffers required at the time, which is convenient for applying for buffer work again later, and IO waste may occur at the same time. The default value of this parameter is 2.0.bgwriter_flush_after:
BgWriter is triggered when the data page size reaches bgwriter_flush_after, the default is 512KB.
3. WalWriter Process
The core idea of Write Ahead Log (also called Xlog) is that the modification of data files must only occur after these modifications have been recorded in the log, that is, the log is written first before the data is written . Using this mechanism can avoid frequent data writing to the disk, and can reduce disk I/O. The database can use these WAL logs to recover the database after a database restart. WalWriter Process is a backend process responsible for ensuring the WAL files are properly written to the disk and its behavior is configurable with the following parameters set in postgresql.conf
#------------------------------------------------------------------------------ |
wal_level:
Controls the level of wal storage. wal_level determines how much information is written to the WAL. The default value isreplica, which adds WAL archive information and includes information required by read-only servers (streaming replicattion). It can also be set tominimal, which only writes the information needed to recover from a crash or immediate shutdown. Setting toLogicalallows WAL streaming to be done in logical decoding scenarios.fsync:
This parameter directly controls whether the log is written to disk first. The default value is ON (write first), which means that the system shall ensure the change is indeed flushed to disk, by issuing the fsync command set bywal_sync_method. While turning off fsync is often a performance benefit, this can result in unrecoverable data corruption in the event of a power failure or system crash. Thus it is only advisable to turn off fsync if you can easily recreate your entire database from external data.synchronous_commit:
This parameter configures whether the system will wait for WAL to complete before returning status information to the user transaction. The default value is ON, indicating that it must wait for WAL to complete before returning transaction status information; configuring OFF can feed back the transaction status faster.wal_sync_method:
This parameter controls the fsync method of WAL writing to disk. The default value is fsync. The available values include open_datasync, fdatasync, fsync_writethrough, fsync, and open_sync. open_datasync and open_sync respectively.full_page_writes:
indicates whether to write the entire page to the WAL.wal_buffers:
The amount of memory space used to store WAL data. The system default value is 64K. This parameter is also affected by the two parameterswal_writer_delayandcommit_delay.wal_writer_delay:
The write interval of the WalWriter process. The default value is 200 milliseconds. If the time is too long, it may cause insufficient memory in the WAL buffer; if the time is too short, it will cause the WAL to continuously write, increasing the disk I/O burden.wal_writer_flush_after:
When dirty data exceeds this threshold, it will be flushed to disk.commit_delay:
indicates the time that the submitted data is stored in the WAL buffer. The default value is 0 milliseconds, which means no delay; when it is set to a non-zero value, the transaction will not be written to the WAL immediately after the commit is executed, but it is still stored in the WAL In the buffer, waiting for the WalWriter process to write to the disk periodically.commit_siblings:
When a transaction issues a commit request, if the number of transactions in the database is greater than the value of commit_siblings, the transaction will wait for a period of time (commit_delay value); otherwise, the transaction is directly written to WAL. The system default value is 5, and this parameter also determines the validity ofcommit_delay.
4. PgArch Process
Similar to the ARCH archiving process in the Oracle database, the difference is that ARCH performs archiving on redo log while PgArch performs archiving on WAL logs. This is needed because the WAL log will be recycled. In other words, the WAL log in the past will be overwritten by the newly generated ones. The PgArch process is responsible for backing up the WAL log before they are overwritten. Starting from version 8.x, these WAL logs can then be used for PITR (Point-In-Time-Recovery), which restores the database state to a certain state at certain period of time. PgArch also has a dedicated section in postgresql.conf to configure its behavior.
# - Archiving - |
- archive_mode:
Indicates whether to perform the archive operation; it can be set to (off), (on) or (always), the default value is off.
- archive_command:
The command set by the administrator for archiving WAL logs. In the command for archiving, the predefined variable “%p” is used to refer to the WAL full path file name that needs to be archived while “%f” indicates the file name without a path (the paths here are relative to the current working directory). When each WAL segment file is archived, the command specified by archive_command will be executed. If the archive command returns 0, PostgreSQL considers the file successfully archived, and then deletes or recycles the WAL segment file. If a non-zero value is returned, PostgreSQL will consider the file was not successfully archived, and will periodically retry until it succeeds.
- archive_timeout:
Indicates the archiving period. When the time set by this parameter is exceeded, the WAL segment is forcibly switched. The default value is 0 (function disabled).
5. AutoVacuum Process
In PostgreSQL database, after performing UPDATE or DELETE operations on the data, the database will not immediately delete the old version of the data. Instead, the data will be marked as deleted by PostgreSQL’s multi-version mechanism. If these old versions of data are being accessed by other transactions, it is necessary to retain them temporarily. After the transaction is submitted, the old versions of the data are no longer required (dead tuples) and therefore the database needs to clean them up to make room. This task is performed by the AutoVacuum process and the parameters related to the AutoVacuum process are also in the postgresql.conf.
#------------------------------------------------------------------------------ |
autovacuum:
whether to start the auto vacuum process automatically, the default value is on.log_autovacuum_min_duration:
This parameter records the execution time of autovacuum. When the execution time of autovaccum exceeds the setting of thelog_autovacuum_min_durationparameter, this incident will be recorded in the log. The default is “-1”, which means no recording.autovacuum_max_workers:
Set the maximum number of autovacuum subprocessesautovacuum_naptime:
Set the interval time between two autovacuum processes.autovacuum_vacuum_threshold and autovacuum_analyze_threshold:
Set the threshold values of the number of updated tuples on the table, if number of tuple updates exceed these values, vacuum and analysis need to be performed respectively.autovacuum_vacuum_scale_factor and autovacuum_analyze_scale_factor:
Set the scaling factor for table size.autovacuum_freeze_max_age:
Set the upper limit of transaction ID that needs to be forced to clean up the database.autovacuum_vacuum_cost_delay:
When the autovacuum process is about to be executed, the vacuum execution cost is evaluated. If the value set byautovacuum_vacuum_cost_limitis exceeded, there will be a delay set by theautovacuum_vacuum_cost_delayparameter. If the value is -1, it means to usevacuum_cost_delayvalue instead. the default value is 20 ms.autovacuum_vacuum_cost_limi: This value is the evaluation threshold of the autovacuum process. The default is -1, which means to use the “vacuum_cost_limit” value. If the cost evaluated during the execution of the autovacuum process exceeds
autovacuum_vacuum_cost_limit, the autovacuum process will sleep.
6. Stat Collector
Stat collector is a statistical information collector of the PostgreSQL database. It collects statistical information during the operation of the database, such as the number of table additions, deletions, or updates, the number of data blocks, changes in indexes…etc. Collecting statistical information is mainly for the query optimizer to make correct judgment and choose the best execution plan. The parameters related to the Stat collector in the postgresql.conf file are as follows:
|
track_activities:
Indicates whether to enable the statistical information collection function for the command currently executed in the session. This parameter is only visible to the super user and session owner. The default value is on.track_counts:
indicates whether to enable the statistical information collection function for database activities. Since the database to be cleaned is selected in the AutoVacuum automatic cleaning process, the database statistical information is required, so the default value of this parameter is on.track_io_timing:
Timely call data block I/O, the default is off, because set to the on state will repeatedly call the database time, which adds a lot of overhead to the database. Only super user can settrack_functions:
indicates whether to enable the number of function calls and time-consuming statistics.track_activity_query_size:
Set the number of bytes used to track the currently executed command of each active session. The default value is 1024, which can only be set after the database is started.stats_temp_directory:
Temporary storage path for statistical information. The path can be a relative path or an absolute path. The default parameter is pg_stat_tmp. This parameter can only be modified in the postgresql.conf file or on the server command line.
7. Checkpointer Process
The checkpointer is a sequence of transaction points set by the system. Setting the checkpoint ensures that the WAL log information before the checkpoint is flushed to the disk. In the event of a crash, the crash recovery procedure looks at the latest checkpoint record to determine the point in the log (known as the redo record) from which it should start the REDO operation. The relevant parameters in the postgresql.conf file are:
# - Checkpoints - |
checkpoint_timeout:
this parameter configures the period of performing a checkpoint. The default is 5 minutes. This means a checkpoint will occur every 5 minutes or whenmax_wal_sizeis about to be exceeded. Default is 1GB.max_wal_size:
this parameter sets the max WAL size before a checkpoint will happenmin_wal_size:
this parameter sets a minimum on the amout of WAL files recycled for future usagecheckpoint_completion_target:
To avoid flooding the I/O system with a burst of page writes, writing dirty buffers during a checkpoint is spread over a period of time. That period is controlled bycheckpoint_completion_target, which is given as a fraction of the checkpoint interval.checkpoint_flush_after:
This parameter allows to force the OS that pages written by the checkpoint should be flushed to disk after a configurable number of bytes. Otherwise, these pages may be kept in the OS’s page cache. Default value is 256kBcheckpoint_warning:
Checkpoints are faily expensive operation. This parameter configures a threshold between each checkpoint and if checkpoints happen too close together thancheckpoint_warningperiod, the system will output a warning in server log to recommend user to increasemax_wal_size
8. Shared Memory and Local Memory
When PostgreSQL server starts, a shared memory will be allocated to be used as a buffer of data blocks to improve the reading and writing capabilities.The WAL log buffer and CLOG buffer also exist in shared memory. Some global information such as process information, lock information, global statistics, etc are all stored in shared memory
In addition to the shared memory, the background services will also allocate some local memory to temporarily store data that does not require global storage. These memory buffers mainly include the following categories:
- Temporary buffer: local buffer used to access temporary tables
- work_mem: Memory buffering used by memory sort operations and hash tables before using temporary disk files.
- maintenance_work_mem: Memory buffer used in maintenance operations (such as vacuum, create index, and alter table add foreign key, etc.).
9. Summary
This blog provides an overview of the core backend processes that drive the PostgreSQL as we see it today and they serve as foundations to database performance tuning. There are many parameters that can be changed to influence the behavior of these backend processes to make the database perform better, safer and faster. This will be a topic for the future.



