1.0 Introduction
My colleague, David, recently published a post “Global Index, a different approach” that describes the work that we are doing to implement global unique index in an approach that does not change current PostgreSQL’s partitioning framework, while allowing cross-partition uniqueness constraint. To implement this, we must first know how PostgreSQL currently ensures uniqueness on a single table with a unique index and then we expand on top of this logic to support cross-partition uniqueness check. This blog of mine here has a rough overview how unique index works in PG. In this blog, I would like to describe the approach we take to ensure cross-partition uniqueness check during index creation in both serial and parallel build.
2.0 Cross-Partition Uniqueness Check in Serial Global Unique Index Build
As described in this blog here, uniqueness is guaranteed by doing a heap scan on a table and sorting the tuples inside one or two BTSpool structures. If 2 tuples with the same scan key are sorted right next to each other, uniqueness violation is found and system errors out. For example, building a global unique index on a partitioned table containing 6 partitions, at least 6 differnt BTSpool will be filled and used to determine uniqueness violation within each partition creation. So if a duplicate exists in another partition, PG currently cannot detect that. So, in theory if we introduce another BTSpool at a global scale that is visible to all partitions and lives until all partitions have been scanned, we can put all index tuples from all partitions in this global spool and determine cross-partition uniqueness simply by sorting it when the last partition scan is finished
This diagram below illustrates the position of the new global level BTSpool (called spool3) and how it can be used to determine cross-partition uniqueness.
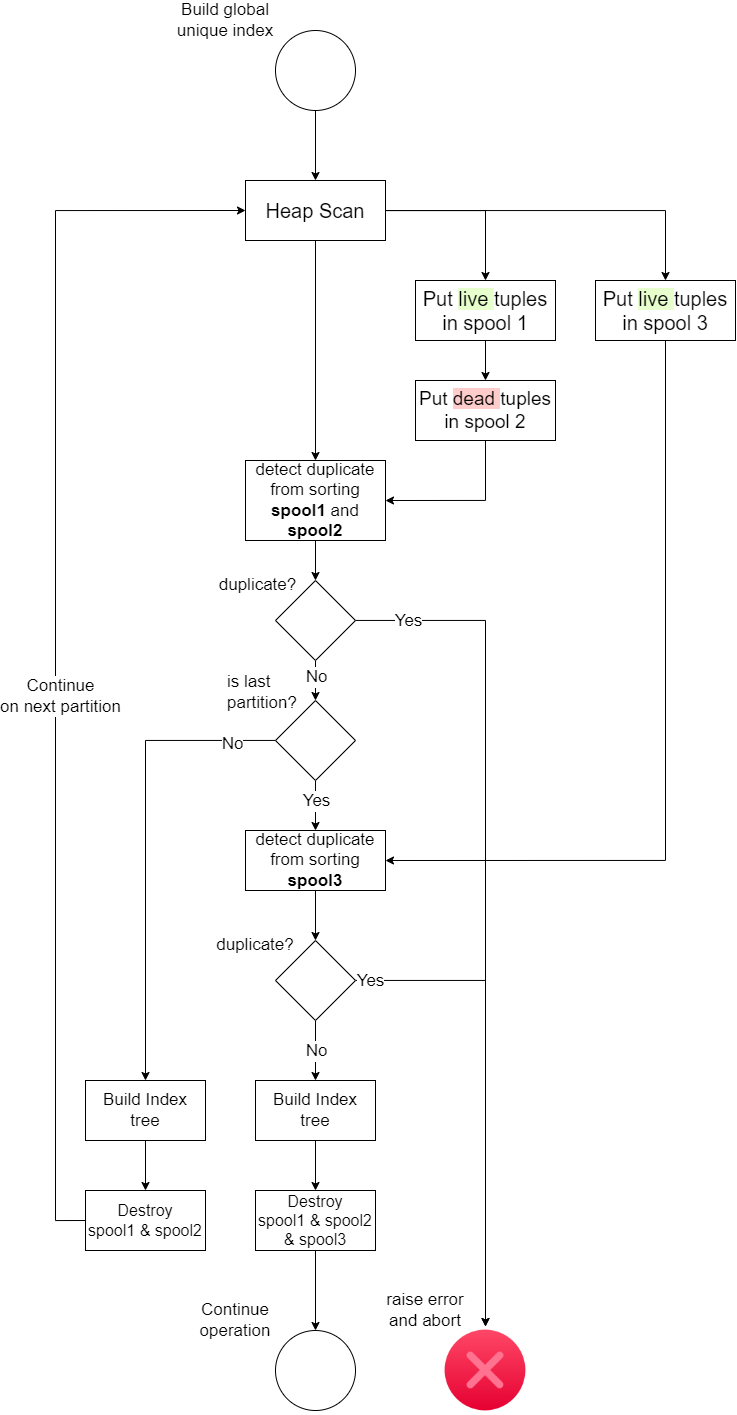
Cross-partition uniqueness check in action:
create table globalidxpart (a int, b int, c text) partition by range (a); |
Some Considerations
How many index tuples can this new global BTSpool hold? Since it needs to hold tuples from all partitions, does it need a lot of memory space allocated?
It uses maintenance_work_mem from postgresql.conf, same as BTSpool1. When it is near capacity, it will start to write tuples on disk as temporary files (also refer to as logical tapes within PostgreSQL, more on this later) instead of in the memory. So the spool can actually hold much more tuples than we thought. Before the final sorting, we will have to do a final merge of all the logical tapes that PG has written out on disk if memory is not enough to hold all tuples, then do a final merge sort to determine uniqueness.
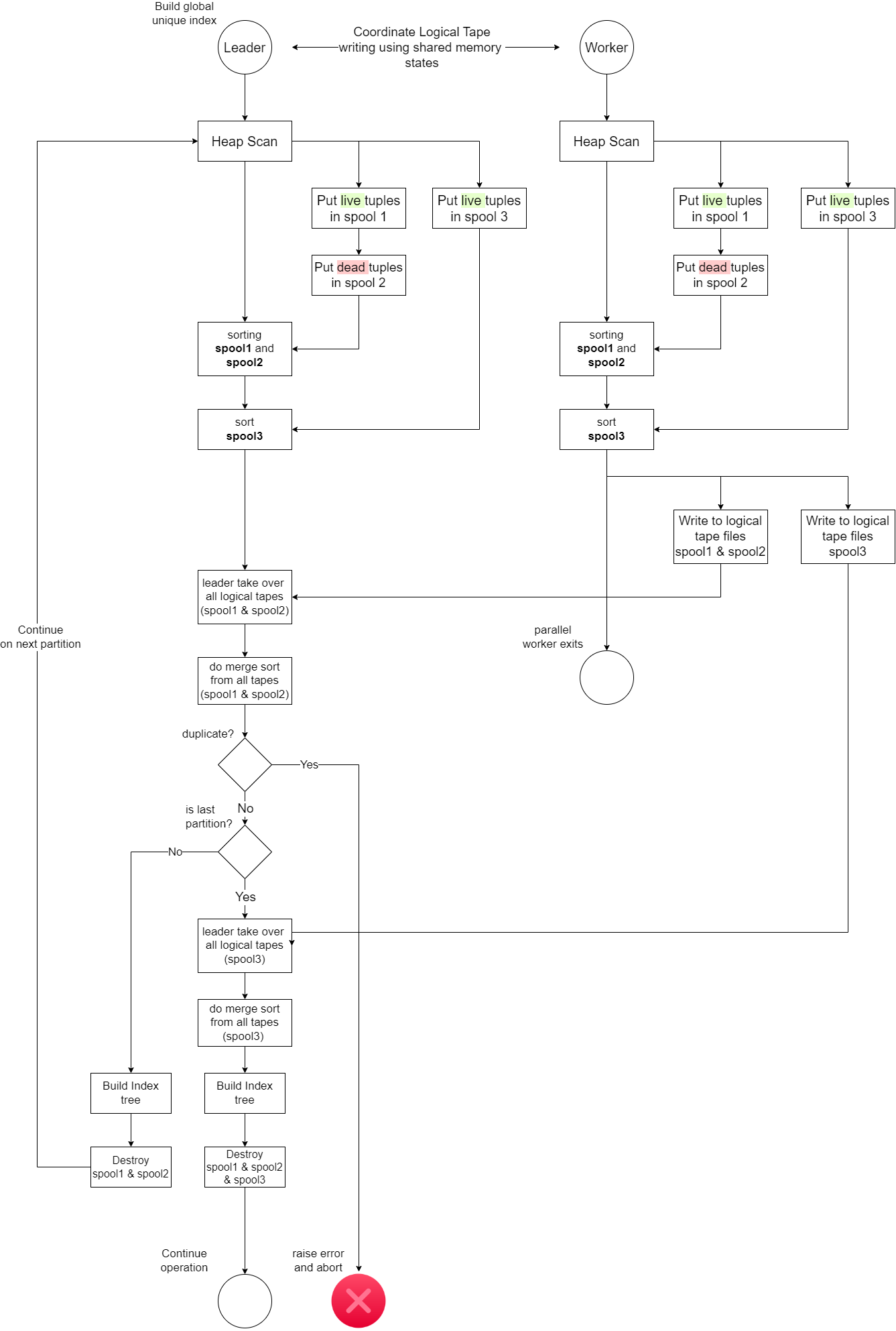
3.0 Cross-Partition Uniqueness Check in Parallel Global Unique Index Build
Cross-partition uniqueness check using a global-scale spool is very straight forward in serial index build case.
PG’s current parallel sorting is much more complex as it uses logical tapes to share and merge intermediate sorted results written on disk as temporary files by each workers. At the final sorting, the leader process take over all logical tapes written out by workers and perform final merge sort to determine uniqueness.
For example, if 3 workers (one of them being the leader) are requested to build a single partition’s index, there will be 3 logical tapes (or 3 temporary files) written out on disk (each being intermediately sorted by each worker before written). The workers use shared memory to coordiate with each other such that they do not write to the same tape files and overwrite each other. When all workers finish, the leader will “Take over all logical tapes”, merge the tapes and perform a final sort. When done, PG will destroy all the parallel workers, which in turn will destroy all logical tape files on disk before moving on to the next partition.
So, to achieve cross-partition check in parallel, we have to retain those logical tape files when we finish sorting one partition. Currently PG will destroy them when a partition’s index build is finished in parallel. If number of worker spawned is X and number of partition is Y, at the last partition build finish, we should have X * Y logical tapes on disk that we need to do merge sort on. We still use a separate spool3 to manage the tapes and persist them until all partitions are finished.
This diagram below illustrates the position of spool3 and how it can be used to determine cross-partition uniqueness in parallel.