Introduction
On November 17-20, 2020, PostgresConf.CN & PGconf.Asia2020 (referred to as 2020 PG Asia Conference) was held online for the very first time! This conference was jointly organized by the PG China Open Source Software Promotion Alliance, PostgresConf International Conference Organization, and PGConf.Asia Asian Community. This conference was broadcast exclusively via the Modb Technology Community platform in China with a record-high number of viewers streaming the conference events. With the great support from these PostgreSQL communities, the conference was held with great success, which brought together the Chinese PG power, major Asian PG contributors and many PostgreSQL experts worldwide to build the largest PG ecosystem in Asia.
About the Conference
Also known as the Asia’s largest open source relational database ecology conference
PostgresConf.CN and PGConf.Asia, for the very first time, were hosted together as one conference online accompanied by additional offline sessions hosted at several reputable university campuses in China.
PostgresConf.CN is an annual conference held by the China PostgreSQL Association for PostgreSQL users and developers. It is also one of the conference series held by PostgresConf Organization. PostgreConf.CN 2019 took place in Beijing, it was very well attended by PostgreSQL users and community members across the globe.
PGCONF.Asia is also an annual PostgreSQL event that took place in Bali Indonesia in 2019, it was a continuation of the PGCONF.Asia event that took place in Tokyo, Japan in 2018. The first PGCONG.Asia conference took place in 2016 in Tokyo, this conference acts as a hub of PostgreSQL related development and technical discussion among PostgreSQL users and developers in the region as well as experts from around the globe.
Learn more about these conferences and the organizers from these resources:
This conference was sponsored by:
Platinum:
Golden:
Silver:
14 Conference Channels over 4 Days!
The conference lasted 4 days at an unprecedented scale. A total of 14 channels, including 5 technical training + 9 main/sub-forum training channels.
- Alibaba Cloud Database Training Session
- Tencent Cloud Database Training Session
- HighGo Software Training Session
- PG Training Institution Charity Session
- PostgresConf Orgnization English Training Session (1 Day)
- the main forum (2 days)
- Chinese sub-forum (2 days)
- English sub-forum A (2 days)
- English sub-forum B (2 days)
- CCF advanced academic forum (1 day)
Over 100 Participating Experts and Scholars Around the World
The number of invited speakers for this conference has set a new record. With the theme of “Born into the World”, the conference gathered 112 technical presentations and more than 100 well-known experts and scholars around the world to provide a grand technical feast for all the participating PGers.
- Guangnam Ni, Fellow of the Chinese Academy of Engineering
- Peng Liu, Vice chairman of China Open Source Software Promotion Alliance and researcher of the Chinese Academy of Sciences
- Zhiyong Peng, deputy director of the database committee of the Chinese Computer Society
- Bruce Momjian, co-founder of PostgreSQL international community and vice president of EDB
- Peter Zaitsev, Founder and CEO of Percona
- Tatsuo Ishii, the original author of Pgpool-ll and founders of PGconf.asian and Japanese PG user association
- Experts from from Alibaba, Tencent, Amazon, JD.com, Inspur, Ping An, Suning, ZTE, HornetLab, Equnix, VMware Greenplum, yMatrix, HighGo Software, Yunhe Enmo, Percona, EDB, NTT, Postgres Professional, Fujitsu, AsiaInfo, Giant Sequoia, Mechuang, Wenwu, Guoxin Sinan, Hytera, Airwallex, Ottertune and many others.
- Professors from Wuhan University, East China Normal University, Harbin Institute of Technology, Shandong University, CCF (China Computer Society) database committee members of Tianjin University
- Professional lecturers from 10 well-known authorized PG training service providers
- And many, many more!
Record High LIVE Streaming Viewers
The number of LIVE streaming viewers at this conference has also hit a new record. Each channel accumulated over 30,000 active LIVE streams, the official conference blog views accumulated over 50,000+ views, and the news reports and articles from media exceeded over 3,000 entries.
Conference Highlights
PostgresConf is an annual event for PostgreSQL developers and users worldwide. This conference attracted core members from the global PostgreSQL community, as well as corporate and individual users who use PostgreSQL.
The PGConf.Asia conference went smoothly for 4 days and it attracted many domestic and foreign audiences worldwide to join the LIVE streaming channels. The conference has 100+ subject sharing sessions, and each session on average accumulated 30,000+ active streams.
The first two days of the conference, several leading internet service vendors such as Alibaba Cloud, Tencent Cloud and database vendor HighGo Software brought a series of rich technical contents related to PostgreSQL, providing tremendous amount of values to the audiences who are willing to learn PostgreSQL database technology
The third and fourth days of the conference consist of numerous technical presentations covering wide range of area of technical interests.
Let’s take a look at some of the highlights of the conference!
Opening Speech by Fellow Guangnam Ni
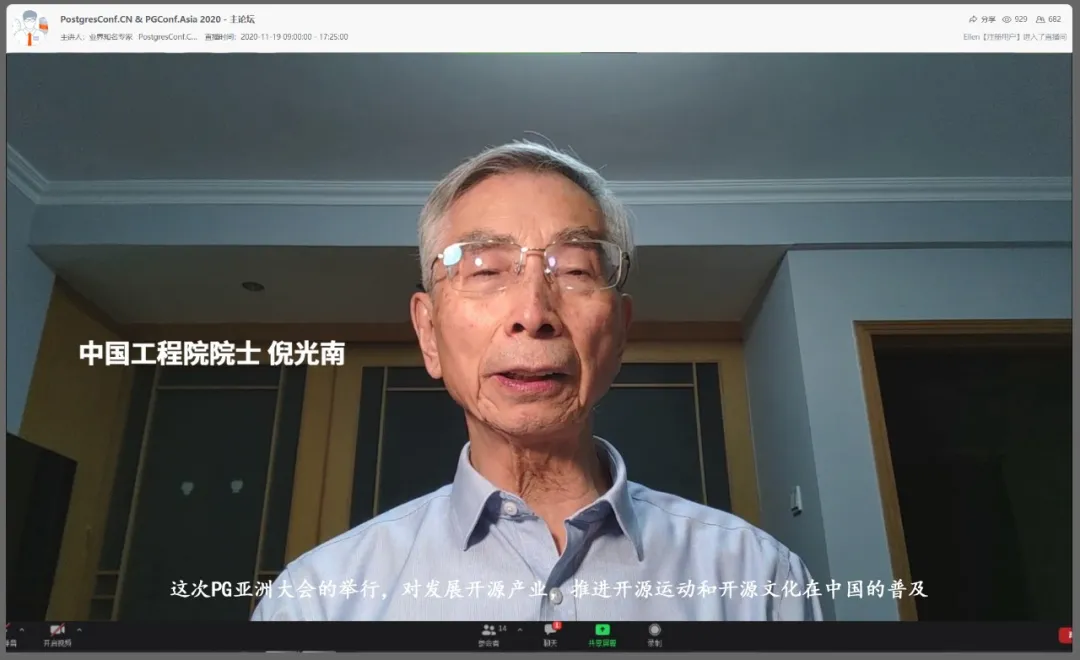
The conference was kick-started by an opening speech by Guangnan Ni, fellow of the Chinese Academy of Engineering and the leader of China’s basic software industry. Fellow Ni first expressed his warm congratulations on the holding of the conference and sincere greetings to the representatives of the participating countries and open source experts. He pointed out that open source is an important trend in today’s world development, and it is profoundly changing the global digital economy and information industry.
This conference brings great value to the development of the open source industry, promotes the open source movement and popularization of open source culture in Chin and also strengthens international exchanges and cooperation. Fellow Ni hopes to use the PGConf Asia Conference platform to realize intellectual exchanges between Asia and the world, achieve higher and higher levels of global cooperation, and contribute to the development of global open source technology. Finally, Fellow Ni wished the conference a complete success, and wished the PG open source ecosystem more prosperity! *”I wish the Chinese PG branch and the Asian PG community prosper and get better and better!”*
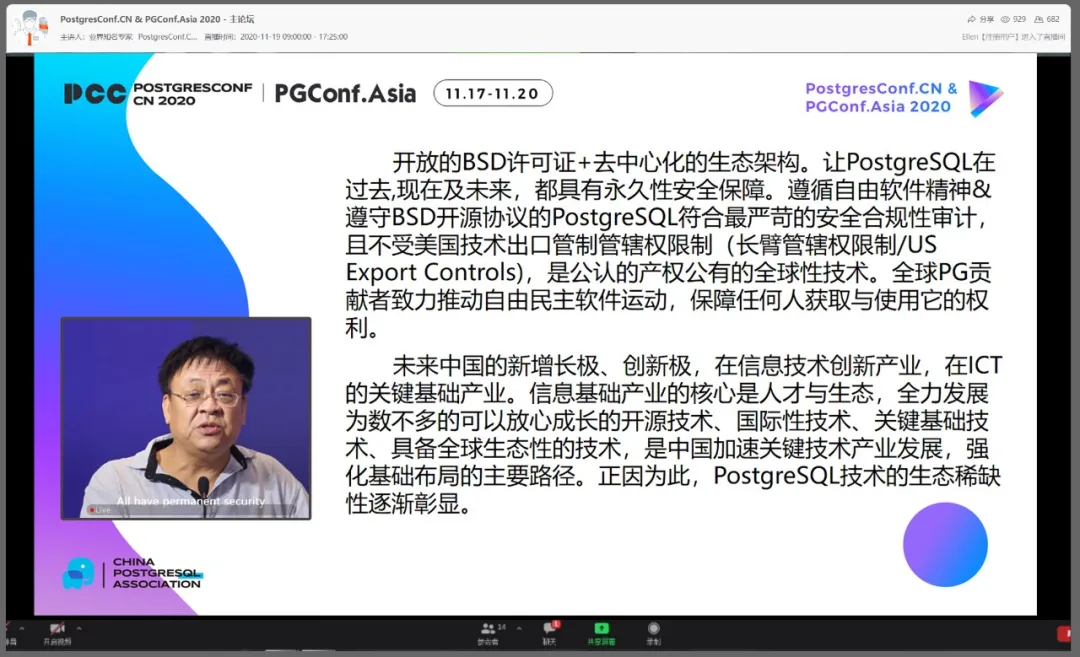
Peng Liu
Peng Liu, executive vice chairman of China Open Source Software Promotion Alliance and researcher at the Institute of Software and Chinese Academy of Sciences, delivered a speech on behalf of COPU. He pointed out that based on the open BSD license + decentralized ecological architecture, PostgreSQL has a permanent security guarantee in the past, present and future. Following the spirit of free software & complying with the BSD open source agreement, PostgreSQL meets the most stringent security compliance audits, and is not subject to US technology export control jurisdiction restrictions (Long Arm Jurisdiction Limitations/US Export Controls). PostgreSQL is a recognized global technology with public property rights and countless global PG contributors are committed to promoting the free and democratic software movement to protect the rights of anyone who obtain and use such software.
Bruce Momjian
Bruce Momjian, co-founder of the PostgreSQL international community and vice president of EDB, shared “Will Postgres Live Forever” speech. He said that any business has its life cycle, and open source PG is no exception, but compared to closed source commercial software, the life cycle of open source software will have more vitality. As long as the source code is valuable, it can always get a new life. In 1996, Postgres got a new life due to the introduction of the SQL standard and the improvement of its functions. The development trend continues to rise today.

Tatuso Ishii
PGconf.Asia and Tatsuo Ishii, the founder of the Japanese PG User Association and the original author of Pgpool-ll, shared “Wonderful PostgreSQL!”. Tatsuo Ishii wrote the WAL system by himself based on Gray’s business thesis, and his creativity is admirable.
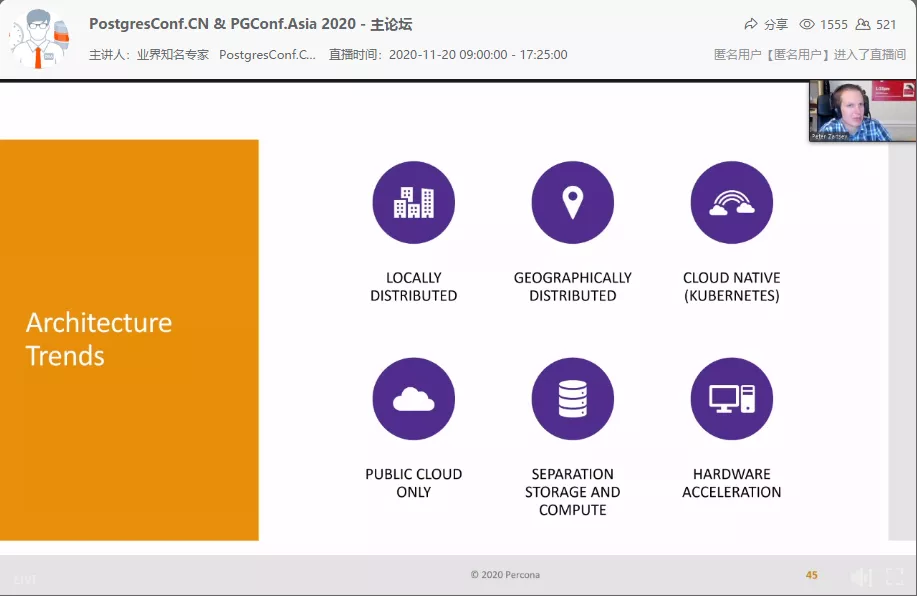
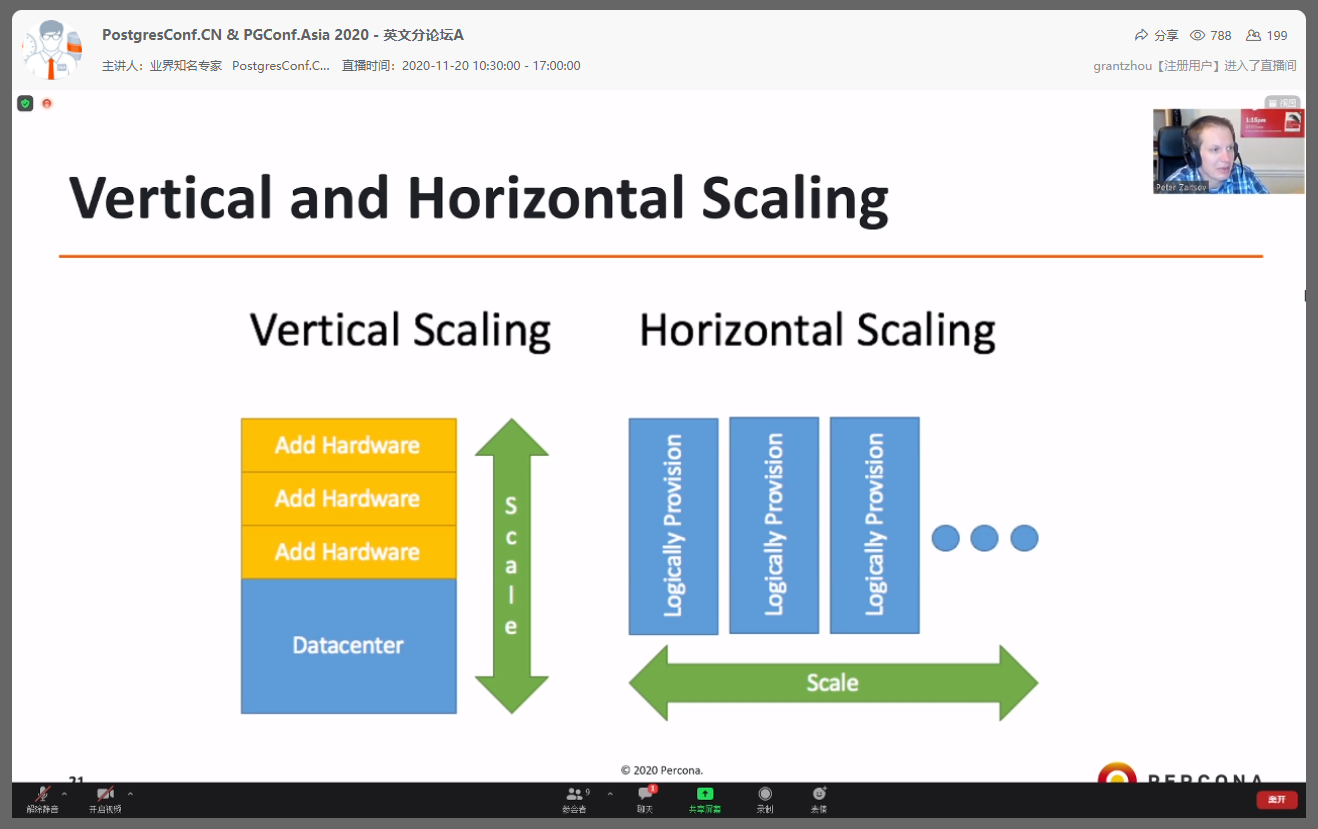
Peter Zaitsev
Percona CEO Peter Zaitsev made a sharing of “The Changing Landscape of Open Source Databases”. He summarized several key points such as distributed, cloud native, storage and computing separation, and hardware acceleration, which basically covered the main focuses of the current database technology development.

Zhiyong Peng
Professor Peng Zhiyong, deputy director of the database committee of CCF China Computer Society, deputy dean of the School of Computer Science of Wuhan University, made a sharing of “My Way from PG to TOTEM”. Professor Peng talked about his 30-years of database research, from leading students to in-depth PG source code research database models, to compiling PG kernel analysis textbooks, to the development of the totem (TOTEM) database.
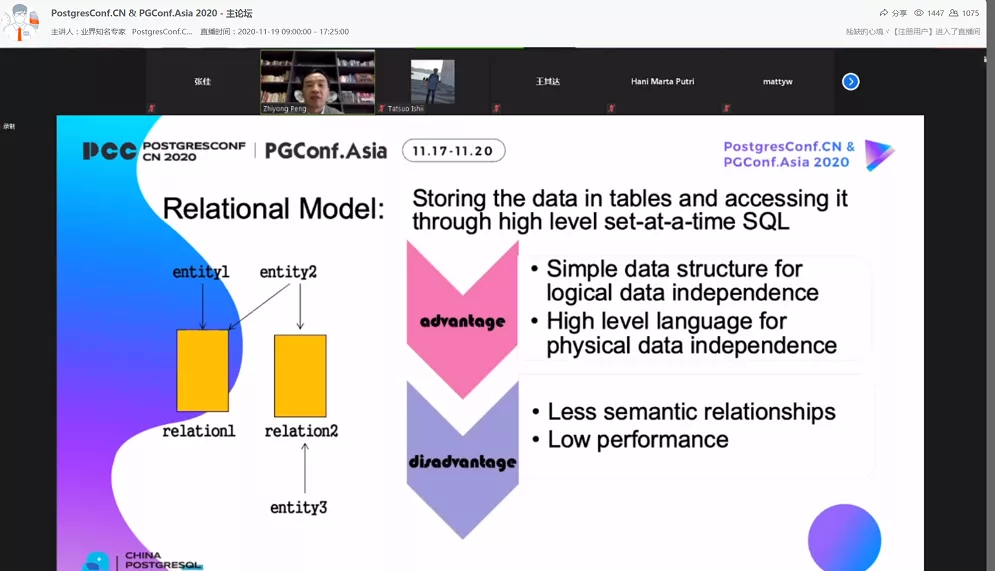
As we all know, PG originated from the University of California, Berkeley. This conference was also fortunate enough to have invited Professor Peng from Wuhan University. Professor Peng has been deeply involved in the PG database for more than 30 years and has led students to in-depth PG source code research database model, to write PG kernel and analysis book. Eventually created the totem (TOTEM) database based on PG. Peng has made outstanding contributions to PostgreSQL talent training and research!
Guoqiang Gai
Guoqiang Gai, the founder of Enmotech, gave a speech on “Observing the elephant: the skills migration from Oracle to PostgreSQL DBA”. Gai gave a principle analysis from a source code perspective through a typical PG rollback problem, encouraging everyone to play with open source databases to learn the source code deeply, emphasizing that DBA is essential to enterprise data management, and every DBA must pass self-employment training to reflect personal value.
Whether it is PG or PG-related database products, its value must always be reflected by helping companies manage core data assets. Here, Gai said that the role of DBA is crucial for the last mile from database products to users. They are the closest partners of databases, whether in client companies, database cloud vendors or software suppliers or integrators. Gai encouraged DBAs to take advantage of open source and analyze in-depth source code to solve problems.
Julyanto SUTANDANG
Julyanto SUTANDANG, CEO of Equnix Business Solutions, gave a very detailed presentation about the professional PostgreSQL certifications and how these certifications can help an individual advance his or her career in PostgreSQL related fields. Certification is one of the best ways to tell your client, or your boss that you are the right person for the job. Whether you are a regular user, a government regulator, a professor or a subcontractor, there will always be a suitable level of PostgreSQL certification for your needs!

Lei Feng
Lei Feng, founder and general manager of Greenplum China founder shared “Greenplum’s open source journey: ecology and community leadership” speech.
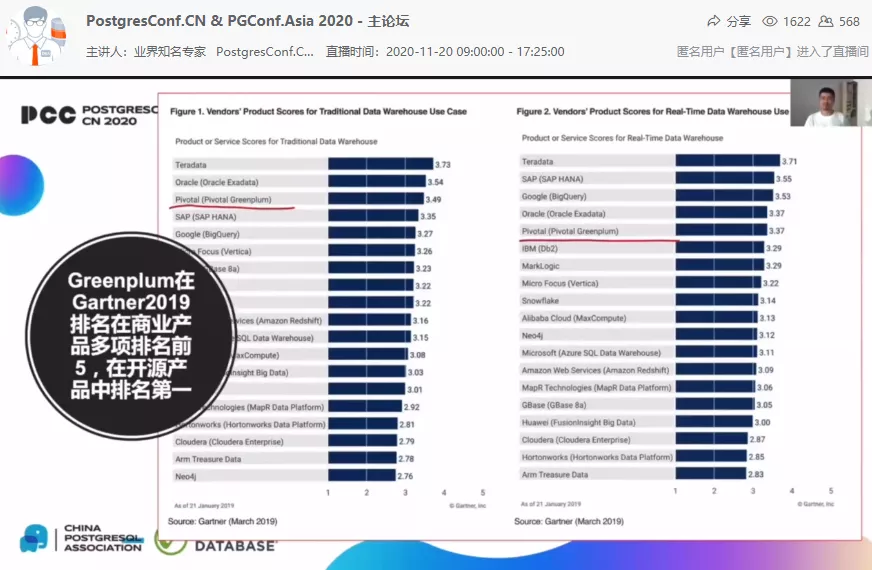
the AI-enabled database is also leading the future development direction of the database. Lei shared the trilogy of their core team’s digital advancement in the cloud era and emphasized that the core competitiveness of database companies in the future will be the exploration and practice of AI models.

Shuxin Fang
Shuxin Fang, general manager of the technical support department of Inspur Business Machines, shared his presentation on “K1 power and PostgreSQL help enterprises to build new normal and new core”.

Zhengsheng Ye
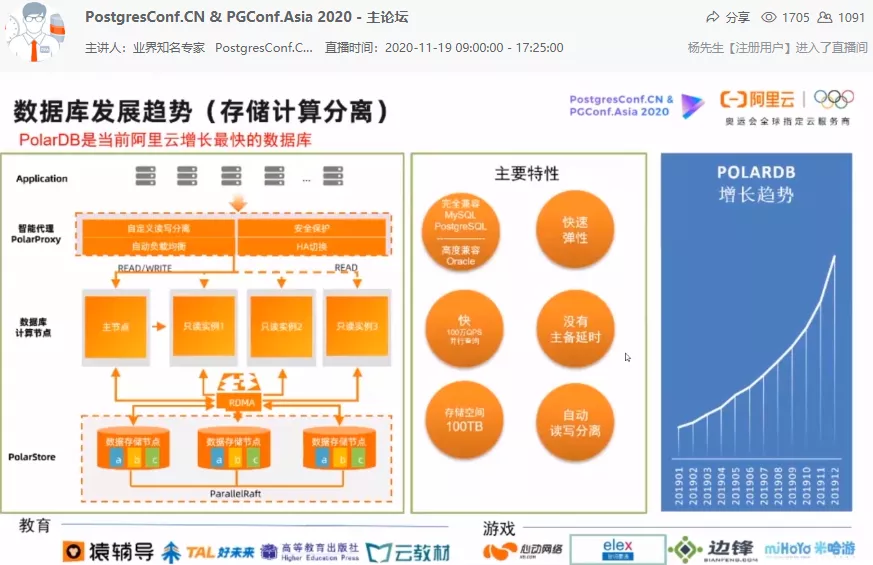
Zhengsheng Ye, general manager of Alibaba Cloud Database Products and Head of Database Products and Operations, shared a speech of “Database Development Trend”.
Yicheng Wang
Yicheng Wang, Deputy General Manager of Tencent Cloud Database, shared the “Database Behind Every WeChat Payment”.
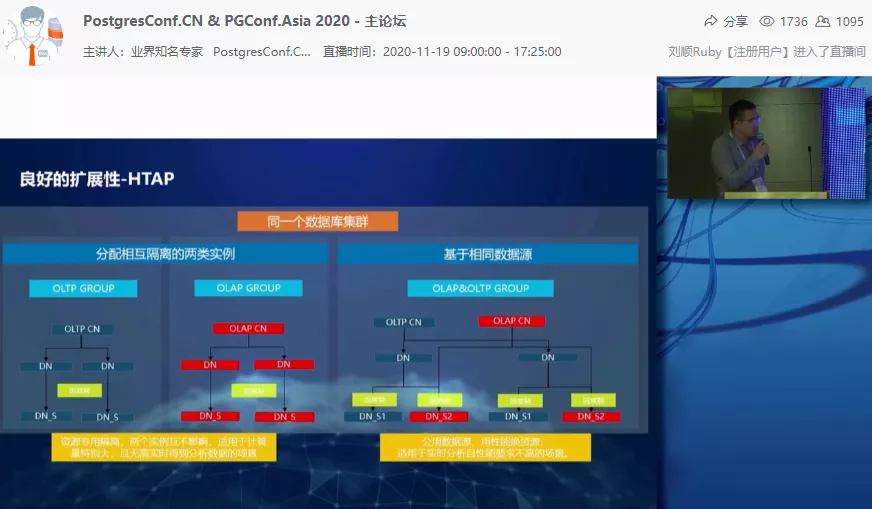
Tencent Cloud uses Tbase’s distributed solution to carry the WeChat payment business, and at the same time, it continues to enhance the core value of the product through cluster scalability, enhanced security, and efficient data compression, providing DBaaS for more enterprise users.

Xiaojun Zheng
Xiaojun Zheng, Chief Scientist of HighGo Software, shared the “Review of Commercial Database Technology Innovation”. With 30 years of senior management experience in several well-known database companies, he elaborated on major innovations in commercial databases in the past 30 years, which has important guiding significance for future database development.
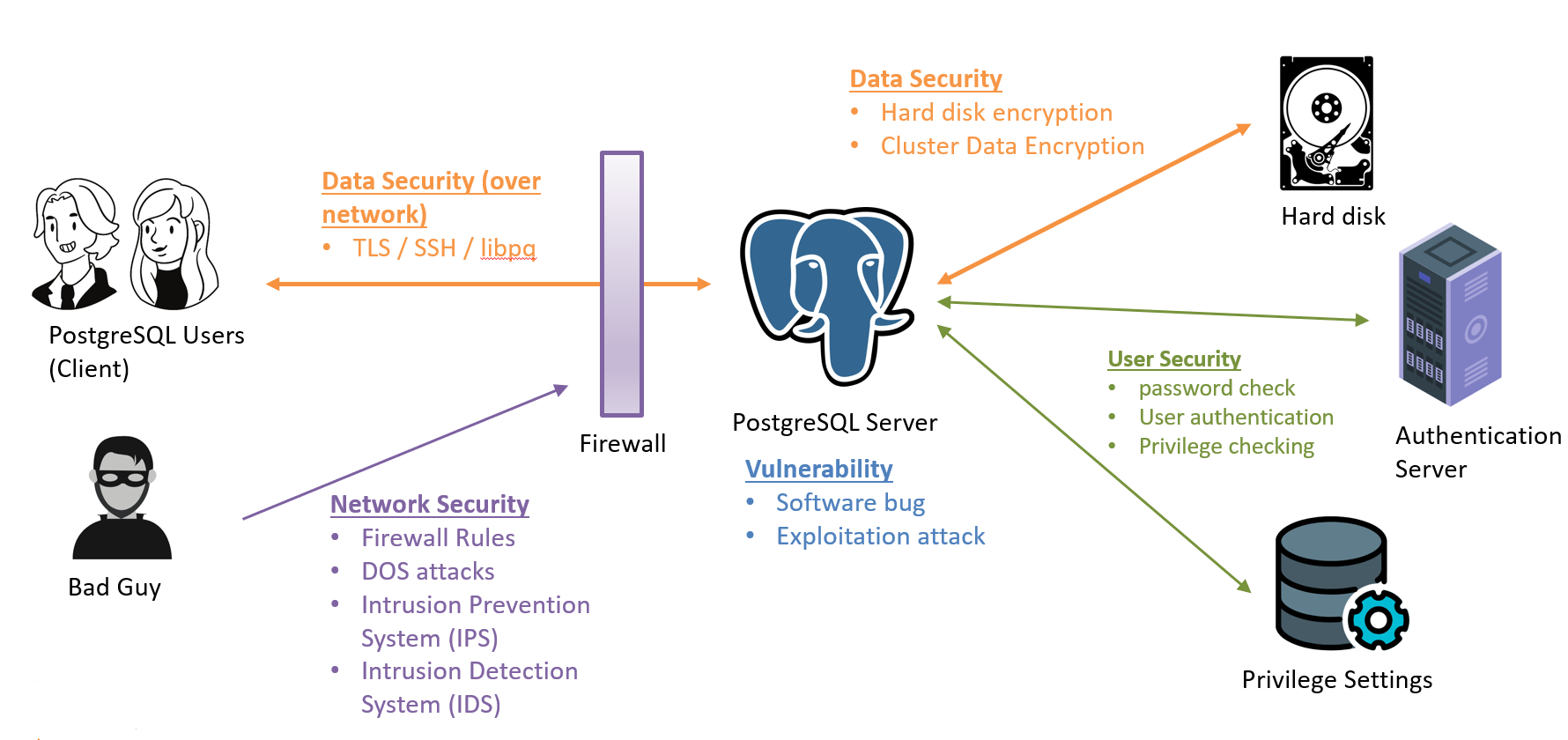
HighGo database (HGDB) values data security with great importance when fulfilling the demands of enterprise users, and it has enhanced the security functions through a variety of technical means, including separation of powers, FDE full disk encryption, security auditing, security marking, etc. More features of the security version can be referred to The image below figure. Not only that, the HighGo enterprise cluster database also has flexible scalability, high availability, and effective load balancing.
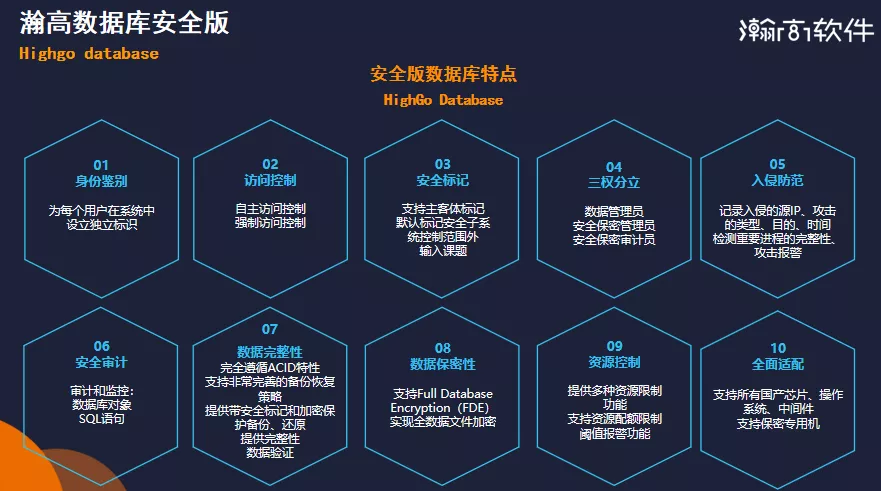
Chaoqun Zhan
Chaoqun Zhan, a researcher of Alibaba Group and head of the OLAP product department of the database product division, shared “Opportunities and Challenges of Cloud Native Data Warehouse”.

The development of database technology is mainly affected by business scenario requirements and development factors of hardware technology. From the perspective of business scenario requirements, Alibaba Cloud, as a domestic leading cloud vendor, mainly integrates PolarDB+ADB full-line database products and integrates PG to respond to users’ various business scenarios.
Zhan shared a cloud-native integrated solution within Alibaba Group, which provides extreme performance and extremely fast and flexible expansion of cloud-native DBaaS.
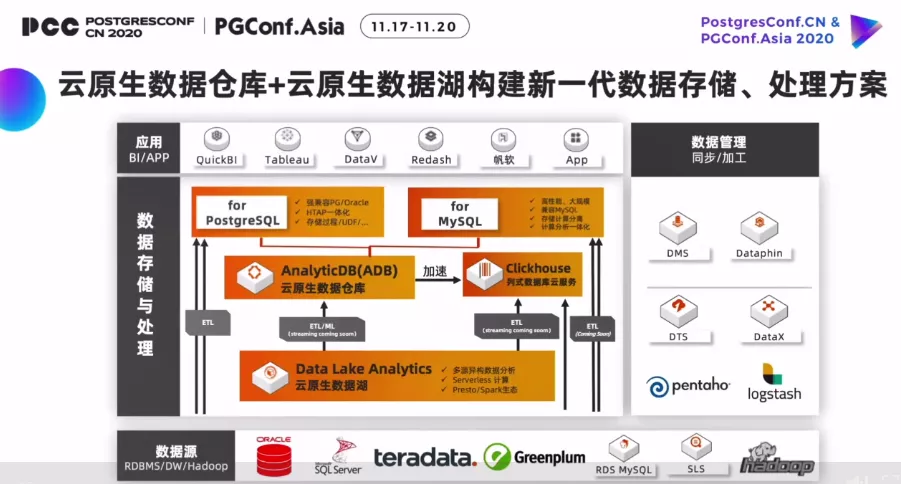
Bohan Zhang
Bohan Zhang, the co-founder of Ottertune, shared effective solutions from the Carnegie Mellon University laboratory for the automatic tuning of PG parameters, and provided DBA recruitment information. If you are interested, please contact Zhang directly
Closing the Conference
On the last day of the conference, Peter Zaitsev, CEO of Percona, shared the topic “17 Things Developers Need to Know About Databases” to help the database developers out there (including PG and non-PG developers) to increase their productivity, their quality of work, maintain a good relationship with DevOps and most importantly, avoid deadly and expensive mistakes!
About China PostgreSQL Assosication
The China PostgreSQL Association is a legitimate and non-profit organization under the China Open Source Software Promotion Alliance.
The association’s main focus is to conduct activities around PostgreSQL, organize operations, promote PostgreSQL, host trainings, contribute to technological innovations and implementations. In addition, the association aims to promote the localization of the database development by bridging the PostgreSQL Chinese community with the International community.
Official Website http://www.postgresqlchina.com