


1. Introduction
PostgreSQL’s 2 phase commit (2PC) feature allows a database to store the details of a transaction on disk without committing it. This is done by issuing PREPARE TRANSACTION [name] command at the end of a transaction block. When the user is ready to commit, he/she can issue COMMIT PREPARED [name] where [name] should match the [name] in PREPARE TRANSACTION command. Because the transaction details are stored on disk with 2PC, the server is able to commit this transaction at a later time even if it crashes or out of service for some time. In a single database instance, the use of 2PC is not critical; the plain ‘commit’ can perform the job equally as well. However, in a larger setup, the data may be distributed on 2 or more database instances (for example, via Foreign Data Wrapper (FDW)), the use of 2PC is absolutely critical here to keep every database instance in sync.
2. Atomic Commit Problem with Foreign Data Wrapper (FDW)
Current postgres_fdw does not support the use of 2PC to commit foreign server. When a commit command is sent to the main server, it will send the same commit command to all of the foreign servers before processing the commit for itself. If one of the foreign node fails the commit, the main server will go through a abort process and will not commit itself due to the failure. However, some of the foreign nodes could already been successfully committed, resulting in a partially committed transaction.
Consider this diagram:
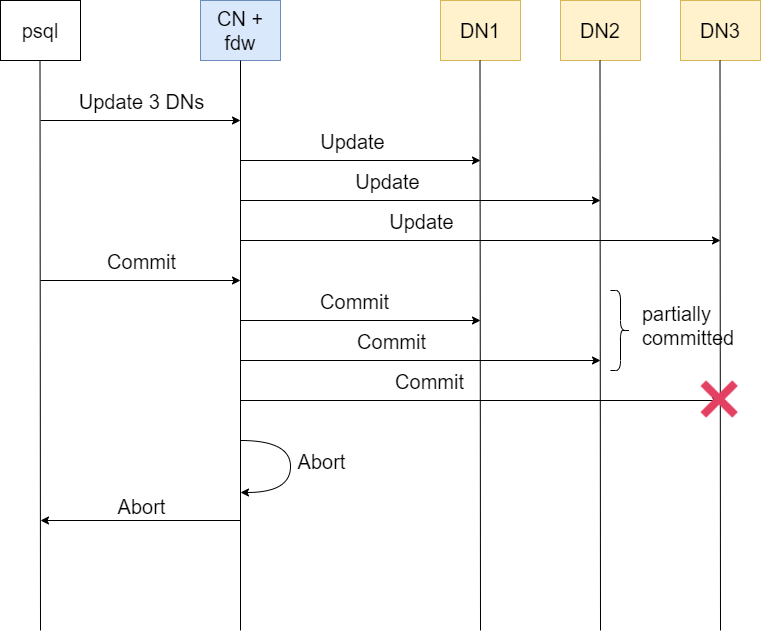
where the CN node fails the commit to DN3 and goes through a abort process, but at the same time, DN1 and DN2 have already been committed successfully and can no longer be rollbacked. This scenario creates a partial commit that may not be desirable.
3. FDW with 2PC Capability
If we were to add a 2PC functionality to current postgres_fdw, instead of sending the same commit to all foreign servers, we let the main server to send PREPARE TRANSACTION instead. The main server should proceed to send COMMIT PREPARE to all foreign servers Only when all of the foreign servers have successfully completed the PREPARE TRANSACTION. If one of them fails at the PREPARE stage, the main server is still able to ROLLBACK those foreign server who have successfully prepared.
Consider this diagram:
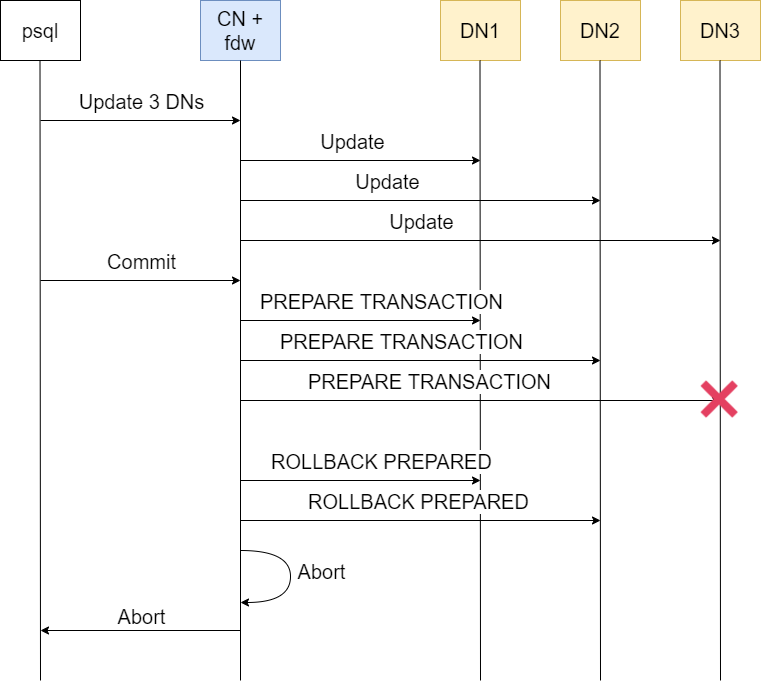
where the CN node fails the PREPARE TRANSACTION to DN3 and sends ROLLBACK PREPARED to DN1 and DN2 before going to the abort process. With the 2PC method, there will not be any partial commits.
3. Handling COMMIT PREPARED Failure?
If a foreign server fails at the PREPARE stage, it is not too late to rollback the rest of foreign servers that have succeeded the PREPARE, so the main server can still send ROLLBACK PREPARED to the foreign servers. However, if a foreign server fails at the COMMIT PREPARE stage, the other foreign servers who have succeeded it can no longer be rollbacked, potentially causing a partial commit as well.
In our implementation, we still allow the main server to continue with the commit even though a foreign server fails COMMIT PREPARED. In addition, we give user a warning about one of the foreign server may not have committed successfully, which leads to a potential partial commit. The foreign server with a failed COMMIT PREPARE will now have something called a “orphaned prepared transaction” that has yet to be committed.
Consider this diagram:
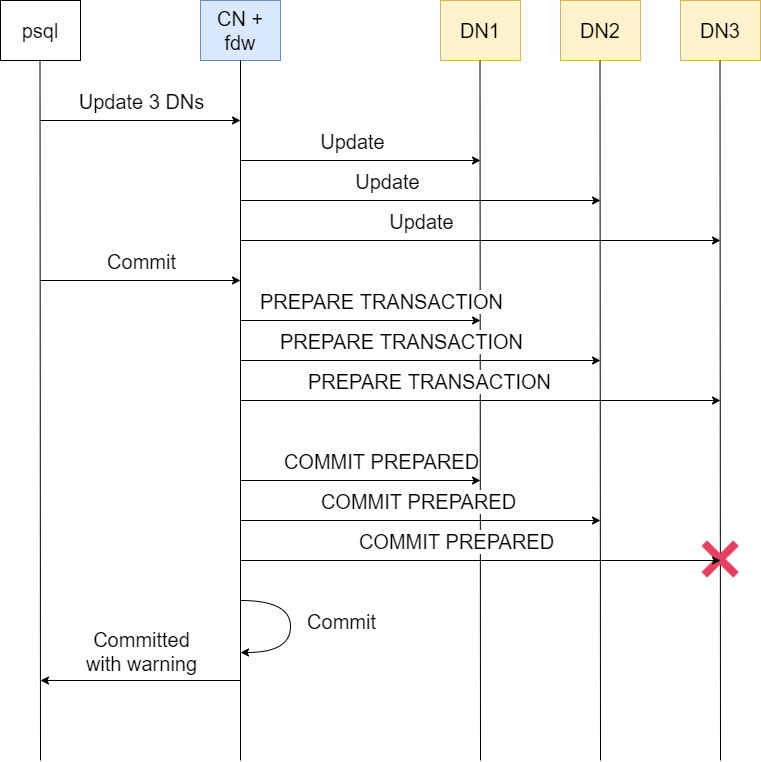
where DN3 fails a COMMIT PREPARED command and the CN node continues the commit with warning.
4. Handling Orphaned Prepared Transaction
Following the above example, if we perform a SELECT query, we will see that DN3 does not have an updated value while DN1 and DN2 have been updated. Also, DN3 still have the transaction prepared and stored in its disk. What’s left to do is to have somebody to login to DN3 and manually run a COMMIT PREPARED command. If that is done successfully, there will no longer be a partial commit.
The way we handle this is to make a orphaned prepared transaction detector at each foreign server and we introduce an intermediate and external global transaction manager (GTM) node that records all the FDW operations. Again, following the above example, when DN3 detects a orphaned prepare transaction, it will make a connection to the GTM node and check if this prepared transaction comes from a CN node. If it is, then we simply let DN3 do a self-commit of the prepared transaction automatically, without any human intervention. If GTM does not have a record, then this orphaned prepared transaction must be created manually by another DN3 user and it should not do anything to it except to just give a warning in the log file.
This is the general concept how we handle atomic commit and orphaned prepared transactions. There may be better and more complex solutions out there but for us, having an intermediate GTM node to coordinate all the operations between CN and DN nodes seems to be the simplest.



