

1. Introduction
Recently, I have had an opportunity to perform some in-depth feasibility study in-memory table using PostgreSQL’s pluggable storage API. The pluggable storage API was introduced Since PostgreSQL v12 and it allowed custom table storage Access Methods (AM for short) to be developed. Some famous examples include zheap from EDB, which aims to store a much more simplified tuple structure to achieve vacuum free storage and zedstore from Greenplum to utilize columnar storage. But they do not utilize in-memory storage and still interacts with existing buffer manager to persist data to disk.
Yes, it would be nice to have in-memory tables if they would perform faster. It would definitely be a very interesting challenge if we could achieve an in-memory table storage engine and design it in a way that will give serious performance advantages using the existing pluggable storage API architecture.
Developing a custom storage AM is no easy task and it requires a very deep understanding on how the current PostgreSQL storage engine works before we are able to improve it. In addition to redefining the tuple structure and custom algorithms to store and retrieve, it is also possible to define our own in-memory based storage module to handle the insertion and retrieval of tuple instead of utilizing the same buffer manager routines like what heap, zheap and zedstore access methods are using.
In this blog, I will briefly talk about the capability of pluggable storage API and share some progress on our in-memory table analysis
2. The Pluggable Storage Access Method API
PostgreSQL already has a pluggable index access method API for defining different index methods such as btree, gin and gist…etc where btree is the default index method today. The desired method can be selected when issuing the CREATE INDEX command like:
CREATE INDEX gin_idx ON movies USING gin (year); |
Before PostgreSQL v12, there was not a pluggable access method for defining table storage and heap was the only access method available. After the introduction of pluggable storage API in v12, it is now possible to create custom storage access methods other than the default heap using similar syntax when creating a table like:
CREATE ACCESS METHOD myheap TYPE TABLE HANDLER myheap_handler; |
There are a total of 38 callback functions provided by the pluggable API that requires to be implemented to develop a new table access method. They are defined in TableAmRoutine structure in tableam.h. It is quite tedious to explain all 38 callback functions here but in short, they primarily have to deal with:
- slot type
- table sequential scan
- parallel table scan
- index scan
- tuple visibility check
- tuple modification, update, insert, etc
- DDL related function, setting relfilenode, vacuum and …etc
- TOAST information
- planner time estimation
- bitmap and sample scan functionality
As you can see, the functionalities to be provided by these callback functions are very critical as they have direct impact on how efficient or inefficient it is to retrieve and store data
3. Using Pluggable Storage API to Achieve in-memory table
The pluggable API does not directly deal with data storage to disk and it has to rely on interacting with buffer manager, which in turn, puts the tuple on disk via storage manager. This is a good thing, because with this architecture, we could potentially create a memory cache module and have the pluggable API’s tuple modification and scanning callbacks to interact with this new memory cache instead for faster tuple insertion and retrieval.
It is possible to achieve a very simple in-memory table with this approach, but there are some interesting considerations here.
- can existing buffer manager still play a role to perform data persistence on disk?
- how large can memory cache size be?
- how and when should memory cache persist data to disk?
- can the access method work if it does not utilize buffer manager routines at all, ie. without CTID?
- is existing buffer manager already acting like a in-memory data storage if its buffer pool is allocated large enough and we don’t mark a page as dirty, so in theory the data always stays in the buffer pool?
3.1 Buffer Manager
Let’s talk about buffer manager. PostgreSQL buffer manager is a very well-written module that works as an intermediate data page buffer before they are flushed to the disk. Existing heap access method and others like zheap and zedstore impementations make extensive use of buffer manager to achieve data storage and persistence on disk. In our in-memory table approach, we actually would like to skip the buffer manager routines and replace it with our own memory cache or similar. So in terms of architecture, it would look something like this where the green highlighted block is what we would like to achieve with in-memory table.
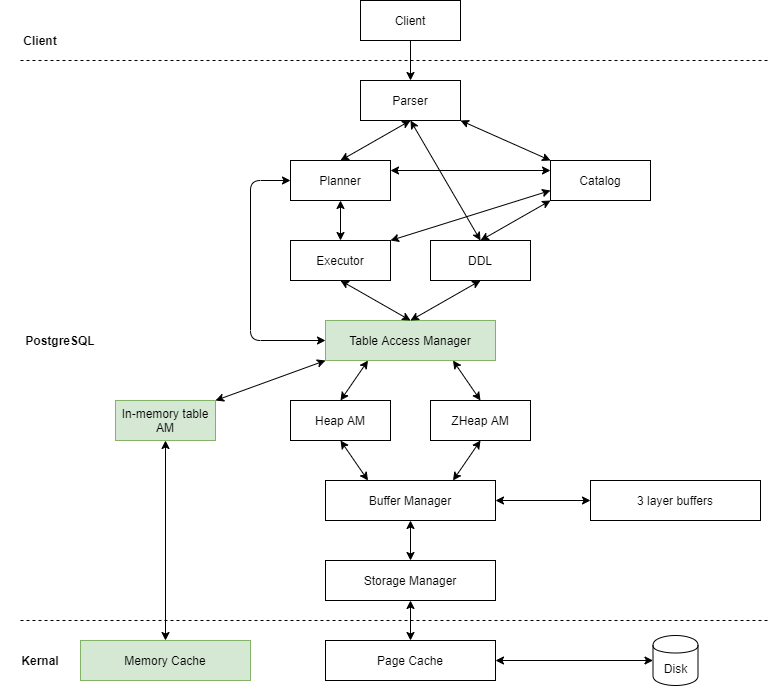
In this approach, the design of the memory cache component would be a challenge as it essentially replaces the functionality of existing buffer manager and utilize in-memory data storage instead. For this reason, the CTID value, which points directly to a specific data page managed by buffer manager, may not be valid anymore if buffer manager is no longer to be used. The concern would be if it is possible to implement a new access method without buffer manager and CTID? Our investigation shows yes, it is possible for the access method to not use buffer manager and CTID at all, but it would require the pluggable API to manually fill the TupleTableSlot when it has retrieved a tuple from memory cache.
3.2 Buffer Manager as In-memory storage?
Another question that rises is that If the existing buffer manager has a large enough buffer pool and we never mark a page as dirty, the buffer manager theoretically will not flush a page to disk and in this case, will we have something very similar to the memory cache module? Theoretically yes, but unfortunately it is not how current buffer manager is designed to do. Buffer manager maintains a ring buffer with limited size and data is flushed to disk when new data enters or when they are deemed as “dirty”. It uses a 3-layer buffer structure to manage the location of each data page on disk and provides comprehensive APIs to the PostgreSQL backend processes to interact, insert and retrieve a tuple. If a tuple resides on the disk instead of in the buffer, it has to retrieve it from the disk.
In terms of time ticks, this is how PG retrieves a tuple from disk:
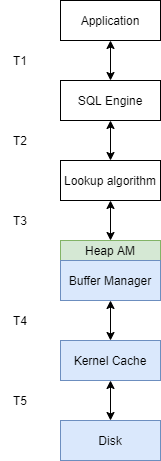
As you can see, it takes T1+T2+T3+T4+T5 to retrieve a tuple from disk. With the approach of in-memory table, we want to cut off the time takes to retrieve tuple from disk, like:
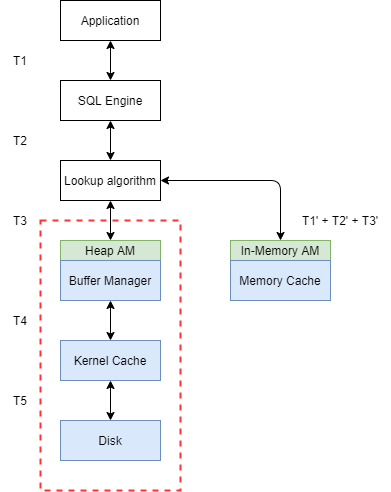
which takes T1’ + T2’ + T3’ to retrieve a tuple from the memory cache. This is where in-memory table implementation can help with performance increase.
3.3 Ideal Size for this New Memory Cache?
The official PostgreSQL documentation recommends allocation of 25% of all the available memory, but no more than 40%. The rest of the available memory should be reserved for kernel and data caching purposes. From this 25% ~ 40% of reserved memory for PG, we need to minus the shared memory allocations from other backend processes. The remainder would be the maximum size the memory cache can allocate and depending on the environment it may or may not be enough. See image below.
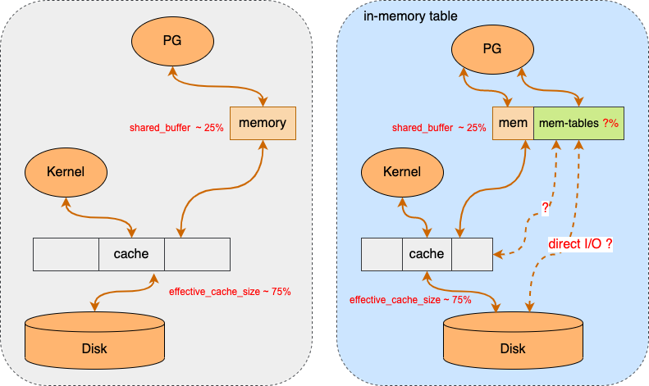
4. Our Approach?
Since our focus is primarily on the memory cache, which is an alternative to existing buffer manager, we would prefer to use the existing Heap tuple as data strucuture to begin with. This way, we can use the existing TOAST, vacuum, WAL, scanning logics and we will primarily focus on replacing its buffer manager interactions with memory-cache equivalent function calls. All this will be done as a separate extension using pluggable API, so it is still possible to use the default Heap access methods on some tables and use in-memory access methods for some other tables.



