



1. Introduction
As an experienced PostgreSQL user, you may have a lot of experience in setting up streaming replication in your database clusters to make multiple backups of your data. But have you wondered how the standby is able to correctly determine if a tuple sent from the primary should be visible to the user or not. In the case where a transaction contains multiple subtransactions, how does the standby determine the visibility in this case? You might say… well it is PostgreSQL so it will just work… This is true. If you are someone who is curious and interested in knowing how PostgreSQL does certain things internally, then this blog may be interesting for you as we will talk about normally transaction and subtransactions and how both affect the standby’s ability to determine tuple visibility.
2. How is Tuple Visibility Determined?
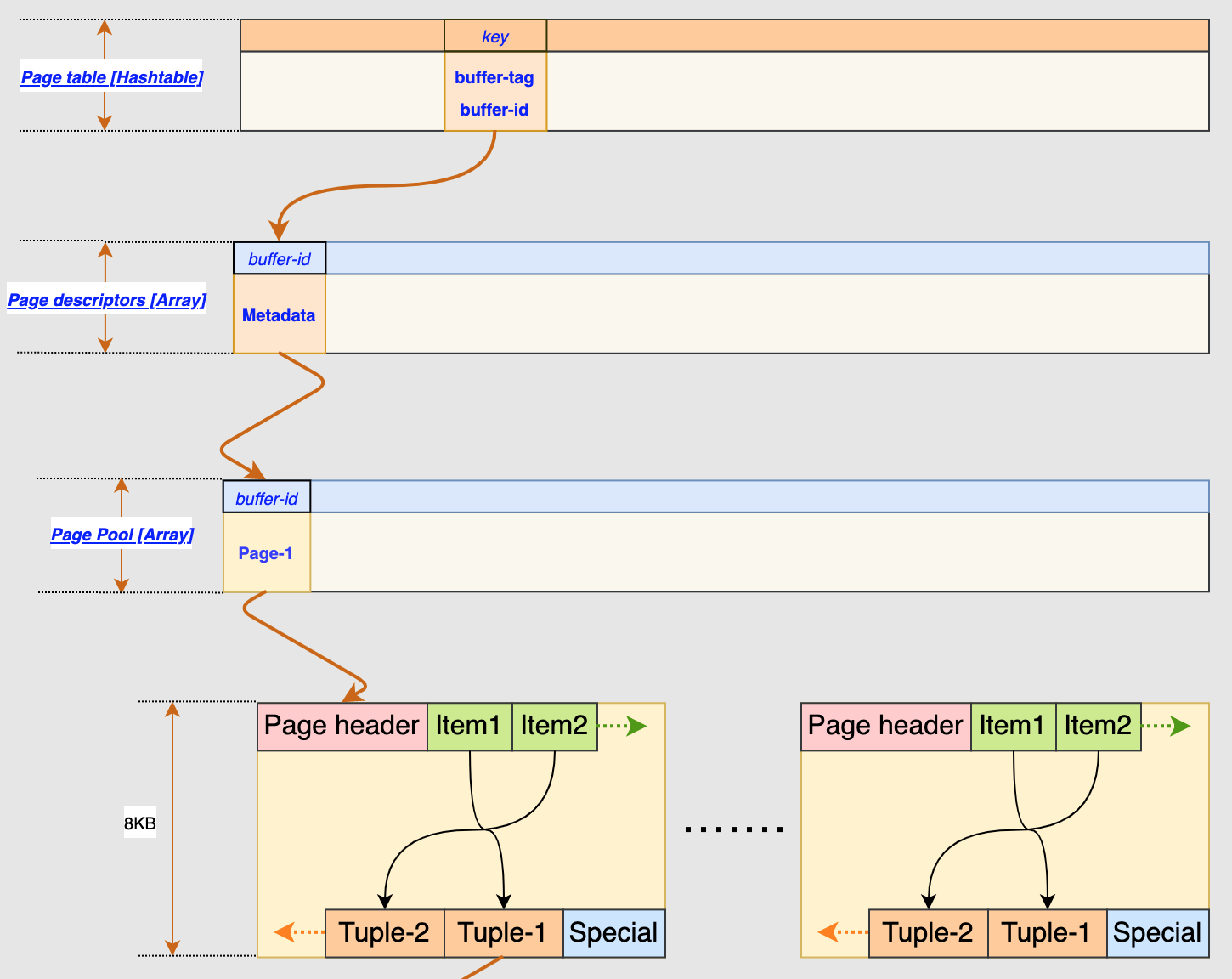
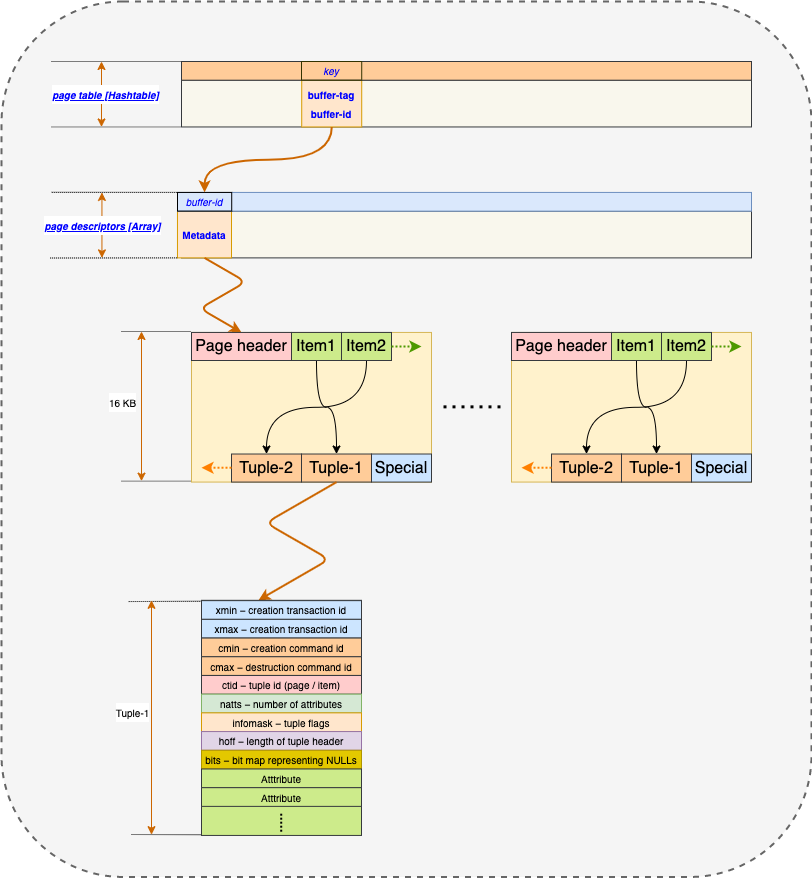
PostgreSQL determines a tuple’s visibility based on the concept of transaction ID (a.k.a txid) and it is normally stored in a tuple’s header as either xmin or xmax where xmin holds the txid of the transaction that inserted this tuple and t_xmax holds the txid of the transaction that deleted or updated this tuple. If a tuple has not been deleted, its t_xmax is 0. There is also another mechanism called commit log (a.k.a clog) where it has information of currently active transaction IDs. When an inserted tuple has a valid t_xmin and invalid t_xmax, PostgreSQL will have to consult the clog first to determine if the txid stored in t_xmin is visible or not, then the result will be stored in the tuple’s hint_bit field about the visibility information such that it does not always have to consult the clog which could be resource intensive. If a tuple has a valid t_xmax, then there is no need to consult the clog as the tuple must be invisible.
This is just the basic ideas of how visibility is determined but it is enough for me to continue with this blog. For more information about visibility, you could refer to this resource
3. What is a Subtransaction?
As the name suggests, it is a smaller transaction that exists within a regular transaction and it can be created using the SAVEPOINT keyword after your BEGIN statement. Normally, when you have issued a BEGIN statement, all the tuples created from the subsequent DML statements such as INSERT or UPDATE will have a txid associated with these tuples and they will all be the same.
When you issue a SAVEPOINT statement within this transaction, all the tuples created from the subsequent DML statements will have a different txid that is normally larger than the main transaction’s txid. When you issue the SAVEPOINT statement again, the txid changes again.
The advantage of Subtransaction is that in a very large transaction, the entire transaction will not be aborted due to an error. It allows you to rollback to the previously created SAVEPOINT and continue to execute the main transaction.
The biggest difference between a subtransaction and a regular transaction is that there is not a concept of commit associated with subtransactions and it will not be recorded in the WAL file. However, if subtransaction is aborted, it will be recorded in the WAL file and subsequently be sent to the standby.
4. How Does a Standby Determines Visibility Information In a Regular Transaction?
Here’s an example of a regular transaction without any subtransactions:
BEGIN; |
In a general case, the above queries will send at least 4 WAL records to the standby during streaming replication. First 3 contain the actual tuple information with t_xmin set to the current transaction ID which is 500 in the example. In other words, before the COMMIT is issued, the standby should have already received 3 WAL records from primary and completed the redo, meaning that the 3 tuples already exist in standby’s memory buffer. However, they are not visible yet because transaction ID 500 does not exist in the standby. It is until the COMMIT is issued in the primary that will subsequently generate a XLOG_XACT_COMMIT WAL record to be sent to standby to notify that transaction ID 500 is now committed and valid. When standby receives the XLOG_XACT_COMMIT WAL record, it will eventually update to its clog so the subsequent SELECT queries can do visibility check against.
5. How Does a Standby Process Visibility Information In a Regular Transaction Containing Subtransactions?
Now, let’s use the same example but add some SAVEPOINT to create subtransactions
BEGIN; |
As you can see, after the creation of SAVEPOINT, the tuple’s t_xmin value will be changed and is no longer equal to the current transaction ID, which is 500 in the example. Before the COMMIT is issued, the standby should have received 9 WAL records, 3 having t_xmin = 500, 3 having t_xmin = 501 and 3 having t_xmin = 502. None of them is visible yet in the standby because these transaction IDs do not exist yet. When the primary issues the COMMIT statement, it will generate a XLOG_XACT_COMMIT WAL record and send to standby containing only the current transaction ID 500 without the 501 and 502.
After the commit, the standby is able to see all 9 tuples that are replicated from the primary. Now, you may be asking…. why? How come the standby knows that txid = 501 and 502 are also visible even though the primary never send a XLOG_XACT_COMMIT WAL record to tell the standby that 501 and 502 are also committed. Keep reading to find out.
Using the similar example, if we rollback to one of the SAVEPOINTs, the primary will send a XLOG_XACT_ABORT WAL record to notify the standby a transaction ID has become invalid.
BEGIN; |
In this example, when doing a ROLLBACK to SAVEPOINT B, a XLOG_XACT_ABORT WAL record will be sent to the standby to invalidate that the transaction ID 502 is invalid. So when primary commits, records having txid=502 will not be visible as primary has notified.
6. The Secret of Standby’s KnownAssignedTransactionIds
In addition to handling the XLOG_XACT_COMMIT and XLOG_XACT_ABORT WAL records to determine if a txid is valid or not, it actually manages a global txid list called KnownAssignedTransactionIds. Whenever a standby receives a heap_redo WAL record, it will save its xmin to KnownAssignedTransactionIds. Using the same example as above again here:
BEGIN; |
Before the COMMIT is issued on the primary, the standby already has txid 500, 501, and 502 present in the KnownAssignedTransactionIds. When the standby receives XLOG_XACT_COMMIT WAL, it will actually submit txid 500 from the WAL plus the 501 and 502 from KnownAssignedTransactionIds to the clog. So that the subsequent SELECT query consult the clog it will say txid 500, 501, and 502 are visible. If the primary sends XLOG_XACT_ABORT as a result of rolling back to a previous SAVEPOINT, that invalid txid will be removed from the KnownAssignedTransactionIds, so when the transaction commits, the invalid txid will not be submit to clog.
7. Summary
So this is how PostgreSQL determines a tuple’s visibility within subtransactions in a streaming replication setup. Of course, there is more details to what is discussed here in this blog, but I hope today’s discussion can help you get a general understanding of how PostgreSQL determines the visibility and maybe it will help you in your current work on PostgreSQL.



