
1. Introduction
This blog talks about a high level description of the mechanism behind PostgreSQL to execute an INSERT query. This process involves many steps of processing before the data is put in the right place. These process normally involves several catalog cache lookup to determine if the destination table exists or several checking on the constraint violations..etc. This blog will mainly focus on the part where the processing handle is passed to the PostgreSQL’s table access method API and its interaction with buffer manager and WAL routines. This is also the core area where an INSERT query is actually executed. If you are a developer looking to understand how PostgreSQL works internally, this blog may be helpful to you…
2. Table Access Method APIs in PostgreSQL
Pluggable table access method API has been made available since PostgreSQL 12, which allows a developer to redefine how PostgreSQL stores / retrieves table data. This API contains a total of 42 routines that need to be implemented in order to complete the implementation and honestly it is no easy task to understand all of them and to implement them. This API structure is defined in tableam.h under the name typedef struct TableAmRoutine
Today I will describe the routines related to INSERT.
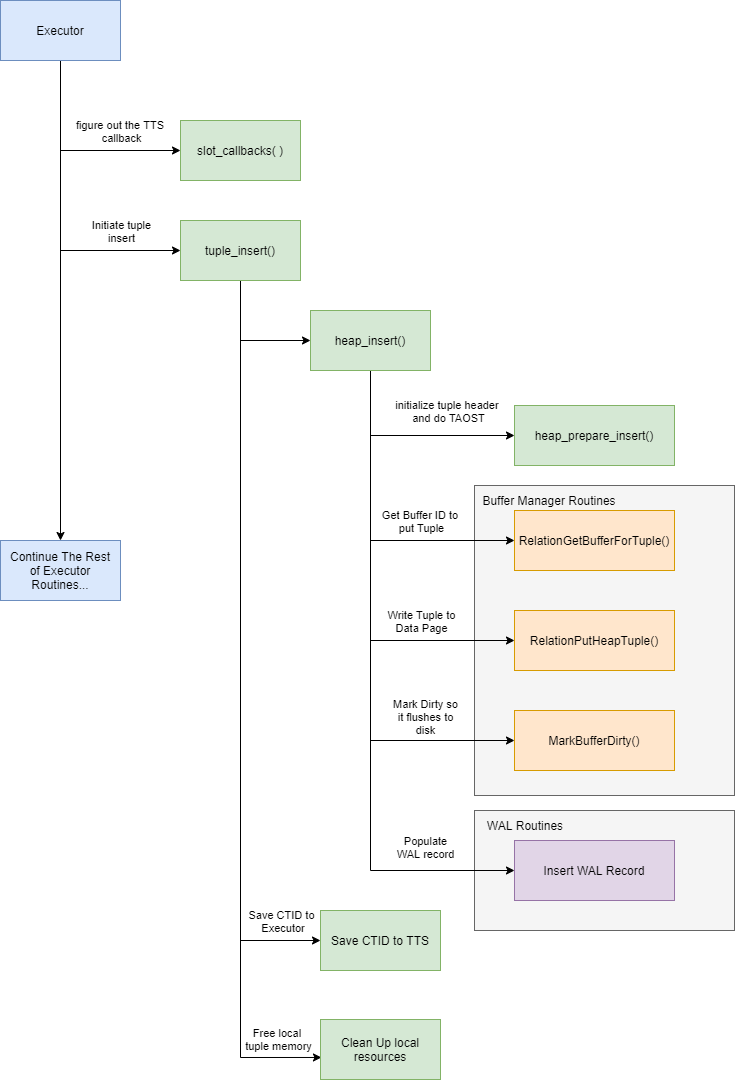
3. INSERT Query Overall Call Flow
A few of the 42 routines will be called by executor just to complete an INSERT query. This section will describe these routines in the order they are called.
3.1 slot_callbacks
const TupleTableSlotOps *(*slot_callbacks) (Relation rel); |
The executor needs to find out which set of tuple table slot (TTS) callback operation this table access method is compatible with. TTS is a set of routines that ensures the tuple storage is compatible between the executor and your access method. The executor will execute the TTS callback to translate your tuple strucuture to TupleTableSlot format in which the executor will understand. The default heap access method uses TTSOpsBufferHeapTuple defined in execTuples.c to handle this operation
3.2 heap_insert
void |
heap_insert is the entry point to perform the actual data insertion and it will undergo several other routines provided by buffer manager and WAL module in order to complete the insertion.
heap_prepare_insert
static HeapTuple heap_prepare_insert(Relation relation, HeapTuple tup, |
This is a subroutine for heap_insert where it will initialize the tuple header contents such as relation OID, infomasks, xmin, xmax values. It will also determine if the tuple is too big that TOAST is required to complete the insertion. These terms and parameters are very technical in PostgreSQL. If you are not sure what exactly they are, you could refer to resources here and here.
RelationGetBufferForTuple
extern Buffer RelationGetBufferForTuple(Relation relation, Size len, |
This is an entry function to access buffer manager resources and all it is doing is ask the buffer manager to return a buffer ID that can be used to store the target tuple. This may sound very straightforward, but there is quite a lot of processing on the buffer manager side to properly determine a desired buffer location.
First, it will do a quick size check. If the input tuple is larger than the size of each buffer block, it will return immediately with error as TOAST has to be used in this case. Then it will try to put the tuple on the same page the system last inserted the tuple on to see if it will fit there. If not, it will utilize the free space map to find another page that could fit tuple. If that does not work out, then buffer manage will allocate a new data page (also referred to as extend) to be used to hold this new tuple. As soon as we have a desired buffer page determined, buffer manager will cache this page in the relation structure such that next time the same relation visits the buffer manager, it knows immediately about the reference to the last inserted block.
RelationPutHeapTuple
extern void RelationPutHeapTuple(Relation relation, Buffer buffer, |
Once we have identified the location of the buffer to store the tuple, the insert routine will then call RelationPutHeapTuple to actually put the tuple in the specified buffer location. This routine will again ask the buffer manager to get a pointer reference to the data page using the buffer ID we obtained from RelationGetBufferForTuple, then add the tuple data using PageAddItem() routine. Internally in buffer manager, it manages the relationship between buffer ID, buffer descriptor and the actual pointer to the data page to help us correctly identify and write to a data page. After a successful write, the routine will save a CTID of the inserted tuple. This ID is the location of this tuple and it consists of the data page number and the offset. For more information about how buffer manager works, you can refer to the resource here
Mark buffer dirty
extern void MarkBufferDirty(Buffer buffer); |
At this point, the tuple data is already stored in the buffer manager referenced by a particular data page plus an offset, but it is not yet flushed to disk yet. In this case, we almost always will have to call MarkBufferDirty function to signal buffer manager that there are some tuples on the page that have not been flushed to disk and therefore in the next checkpoint, it will ensure the new tuples are flushed to disk.
[Insert WAL Record]
Last but not least, after doing all the hassle of finding a buffer location to put our tuple in and mark it as dirty, it is time for the heap_insert routine to populate a WAL record. This part is not the focus of this blog so I will skip the high level details of WAL writing.
3.3 End of the insertion
At this point the insertion of a new tuple data has finished and proper WAL record has been written. The routine will once again save the CTID value that we derived during the data insertion and save this value to the TTS structure so the executor also gets a copy of the location of the tuple. Then it will clean up the local resources before returning.
4. Summary
What we have discussed here is the basic call flow of a simple sequential scan. If we were to visualize the process, it should look something like this: