

1. Introduction
In my previous blog here, I discussed about PostgreSQL’s point in time recovery where PostgreSQL supports an ability to recover your database to a specific time, recovery point or transaction ID in the past but I did not discuss in detail the concept of timeline id, which is also important in database recovery.
2. What is timeline ID and Why it is important?
A timeline ID is basically a point of divergence in WAL. It represents a point, of to be exact, the LSN of the WAL in which the database starts to diverge. Divergence happens when an user performs a point in time recovery or when the standby server is promoted. The timeline ID is included in the first 8 bytes of WAL segment files under pg_wal/ directory.
For example:
pg_wal/000000010000000000000001, indicates that this WAL segment belongs to timeline ID = 1
and
pg_wal/000000020000000000000001, indicates that this WAL segment belongs to timeline ID = 2
Timeline ID behaves somewhat like git branch function without the ability to move forward in parallel and to merge back to the master branch. Your development starts from a master branch, and you are able to create a new branch (A) from the master branch to continue a specific feature development. Let’s say the feature also involves several implementation approaches and you are able to create additional branches (B, C and D) to implement each approach.
This is a simple illustration of git branch:
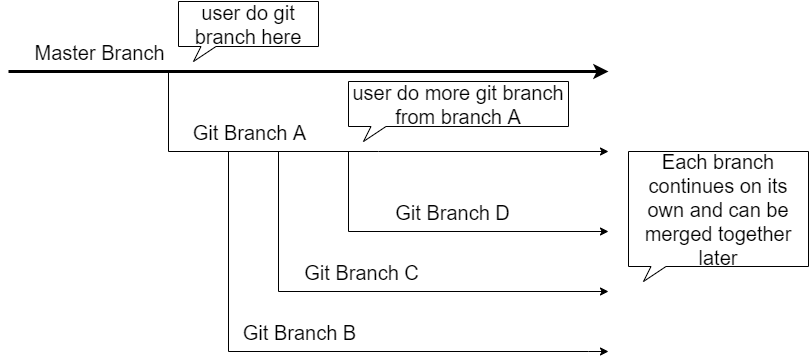
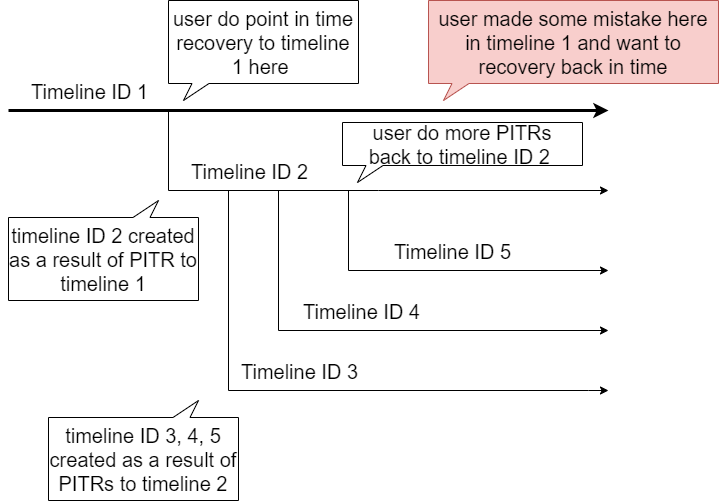
With timeline ID, your database starts from timeline ID 1 and it will stay at 1 for all subsequent database operations. Timeline ID 2 will be created when the user performs a point in time recovery on timeline 1 and all of the subsequnt database operations at this point belong to timeline ID 2. While at 2, the user could perform more PITR to create timeline 3, 4 and 5 respectively.
In the previous PITR blog, I mentioned that you could do PITR based on time, a recovery point, a LSN or a transaction ID but all these can only apply to one particular timeline. In postgresql.conf, you can select a desired recovery timeline by the recovery_target_timeline parameter. This parameter can be 'latest', 'current', or 'a particular timeline ID value'.
With this configuration, an user is able to recovery the database to a particular point of a particular timeline in the past
This is a simple illustration of timeline ID:
3. The History File Associated with a Timeline ID
The history files are created under pg_wal/ directory with a .history postfix when a new timeline Id is created. This file describes all the past divergence points that have to be replayed in order to reach the current timeline. Without this file, it is impossible to tell where a timeline comes from, thus not being able to do PITR.
For example, a history file 00000003.history may contain the following contents
cat pg_wal/00000003.history |
which means that timeline 3 comes from LSN(0/3002B08) of timeline 2, which comes from LSN(0/30000D8) of timeline 1.
4. Importance of Continuous Archiving
With the concept of timeline ID, it is possible that the same LSN or the same WAL segments exist in multiple timelines.
For example: the WAL segments, 3, 4, 5, 6 exist in both timeline 1 and timeline 2 but with different contents. Since the current timeline is 2, so the ones in timeline 2 will continue to grow forward.
000000010000000000000001 |
With more timelines created, the number of WAL segments files may also increase. Sine PG keeps a certain amount of WAL segment files before deleting them, it is super important to archive all the WAL segments to a separate location either by enabling continuous archiving function or using pg_receivewal tool. With all WAL segment files archived in a separate location, the user is able to perform successful point in time recovery to any timeline and any LSN.



